Recurrent Neural Networks-MIT 6.S191
Recurrent Neural Networks-MIT 6.S191
AGENDA
1. Introduction of basic concepts for RNN
움직이는 공을 찍고 있는 동영상을 일시 정지 했다고 상상해 봅시다. 멈춘 화면을 보고 다음 시점에 공이 어느 방향으로 움직일지 예측하는 것은 매우 어려운 일입니다. 하지만 만약 이전 시점들이 주어진다면 어떨까요? 공의 궤적을 통해 다음 시점에 이동할 방향을 예측하기 매우 쉬워질 것입니다. 이처럼 순서에 영향을 받는 데이터를 sequence data라고 부르며 예로는 오디오나 텍스트, 그리고 동영상등이 있습니다.
A sequence Modeling Problem: Predict the Next Word
예를 들어 다음과 같은 문장이 있다고 합시다. “This morning I took my cat for a walk.” 이 문장에서 우리는 앞 부분의 맥락을 통하여 가장 마지막 단어인 walk를 예측하고 싶습니다. 근본적으로 마지막 단어를 예측하기 위하여 우리는 단어를 vectorization할 필요가 있겠죠.
Bag of Words
가장 대표적인 vectorization 방식은 BoW로 불리는 Bag of Words 입니다. 이름 그 대로 단어들의 가방이라는 의미를 지니는데요, 문서(corpus)에 들어 있는 모든 단어의 수를 차원으로 가지는 vector에서 단어가 등장하면 1, 등장하지 않으면 0을 표기하는 방식으로 문장을 embedding(vector화) 하는 방식입니다. 예를 들어보죠. “The food was good, not bad at all.” Vs. “The food was bad, not good at all”라는 두 문장을 보면 다음과 같은 단어들이 등장합니다. [the, food, was, bad, not, good, at, all]. 여기에 보다 직관적인 이해를 위해 apple, eat이라는 단어가 다른 문장에서 등장했다고 가정 하겠습니다(따라서 등장하는 전체 단어는 [the, food, was, bad, not, good, at, all, apple, eat]이 됩니다). 이러한 상황에서 앞의 두 문장을 BoW방식으로 embedding 하면 다음과 같습니다. 첫번째 문장은 [1, 1, 1, 1, 1, 1, 1, 1, 0, 0]와 같이 되겠네요. 그렇다면 두 번째 문장은 어떨까요? 놀랍게도 두 번째 문장 역시 [1, 1, 1, 1, 1, 1, 1, 1, 0, 0]와 같은 형태를 띕니다. “The food was good, not bad at all.”와 “The food was bad, not good at all”는 정 반대의 의미를 가지는데 BoW 방식을 통해 embedding을 하게 되면 두 문장의 벡터가 정확히 동일해지는 크나큰 문제가 생깁니다.
Use a really big fixed window
또 다른 방식이 있습니다. 바로 corpus에 등장하는 모든 단어를 one-hot vector로 encoding 할 수 있지 않을까? 라는 생각에서 나온 방식인데요, 예를 들어 “This morning took the cat … “이라는 문장이 있으면 [1 0 0 0 0 (this), 0 0 0 0 1 (morning), 0 0 1 0 0 (took), 0 1 0 0 0 (the), 0 0 0 1 0 (cat), …]과 같이 vectorization을 하는 것 입니다. 그렇다면 이러한 embedding은 아무런 문제가 없을까요? 학습을 가정해 본다면 위의 문장을 보는 neural network는 무리 없이 this morning을 어떤 특정한 ‘것’으로 인지할 것입니다. 하지만 this morning이 앞 부분이 아니라, 뒷 부분에 등장하는 문장이 있다고 한다면 “This morning took the cat … “이라는 문장으로 학습되고 있는 neural network의 문장 뒤를 담당하는 parameters들은 지금까지 보지 못했던 this morning을 접해야 하기 때문에 this morning을 계속해서 이전과 같은 어떠한 ‘것’ 으로 인지하기는 어렵게 됩니다.
sequence modeling을 위하여 우리는 다음과 같은 사항을 고려해야 합니다 (input이 text라 가정하고 기술하겠습니다)
- 다양한 길이의 문장을 다루어야 한다
- 긴 길이의 문장을 다루어야 한다
- 단어간의 순서 정보를 보존해야 한다
- sequence간의 parameters들이 공유 되어야 한다
이러한 특성을 다루기 위하여 RNN이 등장하였습니다.
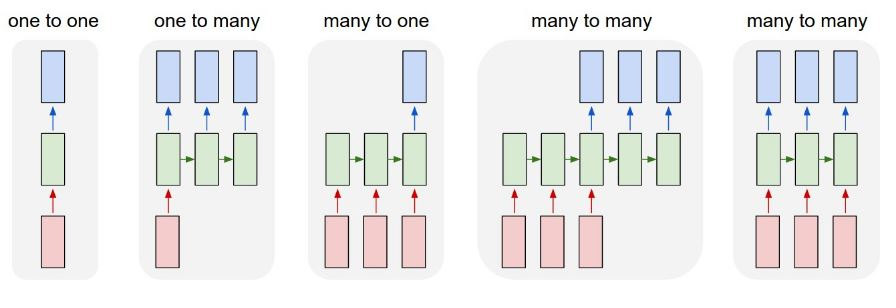
RNN 구조
- One to One - 전통적인 NN -> sequence를 다루는데 적합하지 않음
- Many to One - 감성분석과 같은 분류
- Many to Many - 매우 다양하게 활용 가능 : 본 수업의 타겟
위에 기재되어 있는 RNN을 아래 그림과 매칭시켜 보시면 이해가 편하실 것 같습니다.
Standard RNN gradient flow
최초에 제안된 RNN은 아래와 같이 생겼습니다.
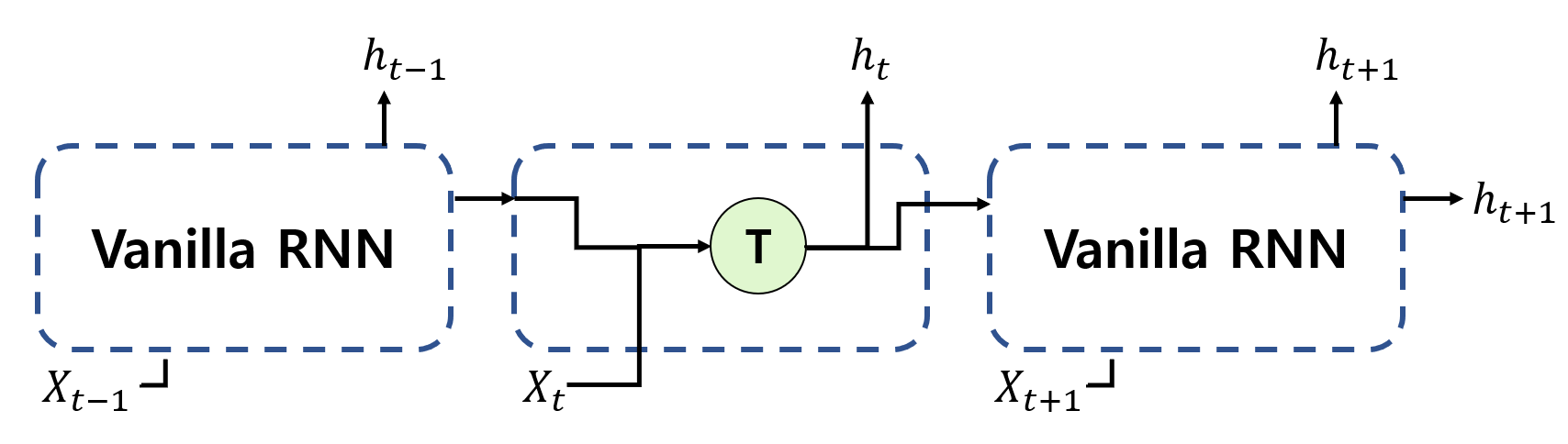
최초에 제안된 RNN을 vanilla RNN이라 부르며, cell의 연산은 아래의 식을 따릅니다:
\(h_t = tanh(x_t\mathbf{U}+h_{t-1}\mathbf{W} + b_t).\)
위 식에서 확인할 수 있듯이 vanilla RNN은 이전 state의 hidden vector와 현재 state의 input vector간의 선형 결합으로 이루어져 있습니다. 이러한 재귀적인 구조를 통해 CNN과는 다르게 데이터의 sequence 정보를 보존할 수 있지만 아래와 같은 문제점들을 지닙니다.
Exploding gradients
많은 gradients value가 1보다 큰 경우를 의미하며, 이 경우 gradient가 발산하여 어떠한 optimization도 할 수 없게 됩니다. 이러한 문제는 gradient clipping을 통해 다소 간단하게 해소 가능 합니다. Gradient clipping이란 단순하게 gradient가 계속 커지는 것을 막기 위하여 특정한 값을 곱해주어 크기를 축소시키는 방법 입니다.
Vanishing gradients
사실 이 부분이 해소가 어려워 vanilla RNN이 등장했을 때 많이 환영받지 못하였습니다. Vanishing gradients 문제는 많은 gradients value가 1보다 작은 경우 gradient가 사라지는 문제를 뜻합니다. 이를 해소하기 위하여서는 activation function을 변경하거나, 좋은 Weight 초기화 방법을 사용하는 방식이 있지만 이보다는 근본적으로 모델 구조를 변경하는 것이 가장 강건한 방식 입니다.
vanishing gradient가 왜 문제인가?
Gradient가 계속 작아지는 상황을 상상해보죠. 20단어로 이루어진 문장이 있는데 10단어째 부터 gradient가 매우 작아진다면 결국 첫 번째 단어까지 gradient 전파가 불가능해겠죠? 이런 상황에서는 RNN의 학습이 제대로 이루어질리 만무합니다. 이를 해소하기 위하여 수업에서는 아래와 같은 트릭들을 설명합니다.
- Trick 1 : Activation function을 tanh에서 ReLU를 사용하는 것이 도움이 된다
- Trick 2 : parameter 초기화를 identity matrix로 하면 도움이 된다
- Trick 3 : LSTM, GRU와 같은 gated cell을 사용하는 것이 가장 강건한 해결책이 된다
LSTM에 대하여 알아보자!
vanilla RNN에서 발전한 형태인 LSTM에 대해서 알아보겠습니다. 우선 모델 구조는 아래와 같습니다.
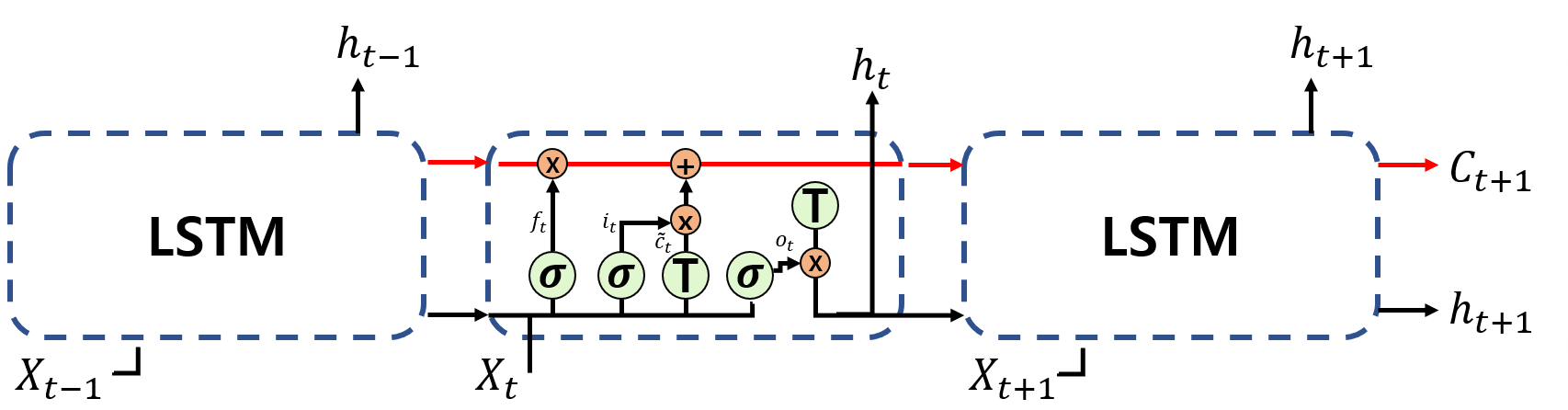
딱 보기에도 RNN보다 훨씬 복잡한 구조임을 확인할 수 있습니다. 수식을 통해 어떤 부분이 추가되었는지 살펴보죠.
LSTM:
\(f_t = \sigma(\mathbf{W}_f\cdot [h_{t-1},x_t]+b_f),\)
\(i_t = \sigma(\mathbf{W}_i\cdot [h_{t-1},x_t]+b_i),\)
\(\widetilde{C}_t=tanh(\mathbf{W}_c\cdot[h_{t-1},x_t]+b_c),\)
\(C_t=f_t\times C_{t-1} + i_t \times \widetilde{C}_t,\)
\(o_t = \sigma(\mathbf{W}_o\cdot [h_{t-1},x_t]+b_o),\)
\(h_t = o_t \times tanh(C_t).\)
LSTM은 기본적인 RNN이 sequence가 길어짐에 따라 발생하는 gradient descent문제를 해결하고자 등장하였습니다. LSTM은 input gate ($i_t$), output gate ($o_t$), 그리고 forget gate ($f_t$)와 같은 gate unit을 활용합니다. 각 gate들은 sigmoid layer로 구성되어 있으며 output이 1 인 경우 해당 값을 온전히 유지하게 되며, 0인 경우에는 전혀 사용하지 않습니다. 이러한 연산을 통하여 기존에 vanilla RNN에서는 할 수 없었던 sequence의 정보를 얼마나 기억할지와 잊어버릴지를 파라미터를 통하여 학습할 수 있게 된 것이죠! 사실 LSTM이 가지는 가장 큰 특성은 cell state이며 LSTM의 구조를 나타내는 Figure 3의 상단 부분 수평선이 바로 그 cell state입니다. Cell state는 gates들을 통하여 정보를 추가하거나 제거하는 역학을 맡고 있습니다. LSTM는 우선 forget gate를 통하여 버릴 정보를 선택합니다. Forget gate와 input gate는 현 시점의 input과 이전 시점의 hidden state를 받아 0과 1 사이의 output을 가지며, 앞의 두 gates들을 통하여 LSTM cell은 잊을 정보와 기억할 정보를 cell state에 update 하게 되는 것이죠. $\widetilde{C}_t$는 최종적으로 updated된 cell state를 나타냅니다. LSTM의 output ($h_t$)은 vanilla RNN과 같이 이전 state의 hidden state value와 현재의 output을 통해 산출됩니다.
GRU 대하여 알아보자!
LSTM과 같이 vanishing gradient문제를 해결하면서도 파라미터의 수를 줄여 계산 복잡도를 감소시키기 위해 GRU model이 소개되었습니다. GRU는 cell state와 hidden state를 결합하여 하나의 hidden state로 나타냄과 동시에 forget gate와 input gate를 결합한 update gate를 제안 합니다. Figure 4에서 확인할 수 있듯이 GRU의 구조는 LSTM에 비해 훨씬 간단합니다.
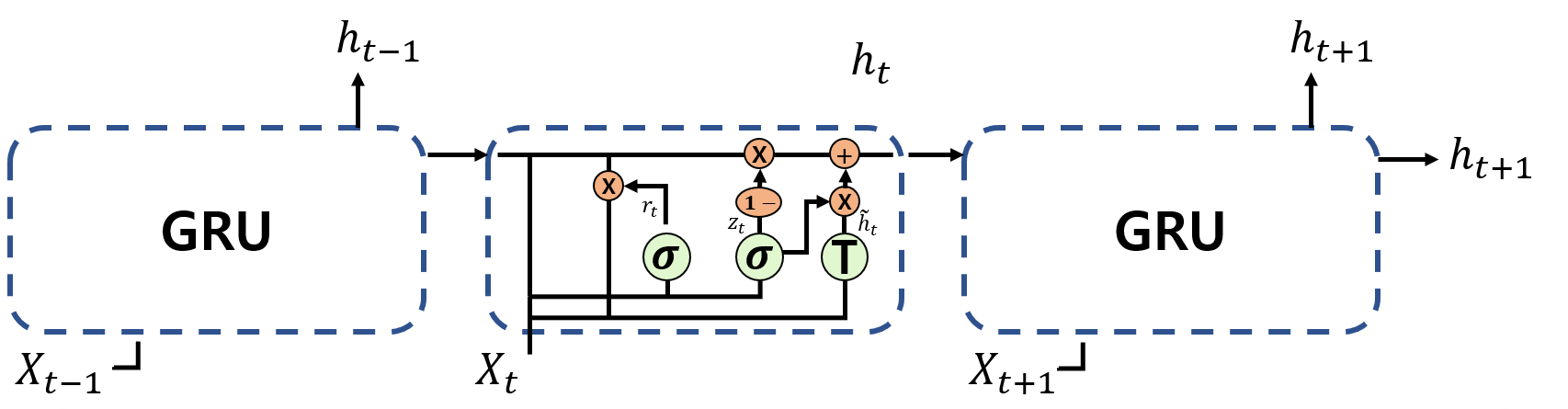
GRU가 가지는 cell들은 아래와 같습니다:
GRU:
\(z_t = \sigma(\mathbf{W}_z\cdot [h_{t-1},x_t]+b_z),\)
\(r_t = \sigma(\mathbf{W}_i\cdot [h_{t-1},x_t]+b_r),\)
\(\widetilde{h}_t=tanh(\mathbf{W}_c\cdot[h_{t-1},x_t]+b_c),\)
\(h_t=(1-z_t)\times h_{t-1} + z_t \times \widetilde{h}_t.\)
$z_t$는 update gate의 계산 방식입니다. GRU의 reset gate는 모델이 과거 정보의 얼마만큼을 다음 스텝으로 전달해야 하는지 결정하는데 도움을 줍니다. $r_t$가 바로 reset gate이며 이름처럼 지난 정보를 얼마나 사용하지 않을지를 결정하고 있습니다. 나머지 부분은 vinilla RNN과 LSTM에서 보신 것과 매우 흡사 합니다.
RNN application
RNN은 다음과 같이 여러 방면에서 활용되고 있습니다.
- Music generation
- Sentiment classification
- Machine translation
마무리
사실 sentiment classification의 경우 Yoon Kim 님의 textCNN이 나온 이후로 CNN구조에 비해 크게 좋은 성능을 보이고 있지 못하고 있습니다. CNN에서도 text의 감성이나 주제를 분류하기 위하여 많은 연구들이 제안되어 왔었구요. 현재 RNN의 가장 큰 활용 분야는 역시 machine translation과 (visual)Q&A가 아닐까 싶습니다. BERT와 같은 훌륭한 pretrained model도 나왔고 앞으로 계속 더 발전하지 않을까 라는 개인적인 생각이 있습니다.
사실 많은 수업에서 CNN을 RNN보다 먼저 다루고 있는 것으로 알고 있습니다만, 본 강의에서는 RNN을 2강에서, 그리고 CNN을 3강에서 다루고 있습니다. 그럼 3강에서 CNN으로 찾아뵙겠습니다.
Leave a comment