Deep Learning for Computer Vision-MIT 6.S191
AGENDA
1. Introduction of basic concepts for CNN
컴퓨터는 사물을 어떻게 인식할까요? 우리가 이미지를 보는 것 처럼 똑같이 인식할 수 있을까요? 인지공학이나 뇌공학을 모르기 때문에 확신할 수는 없지만 아마 그렇지 않을 것 같습니다. 그 이유는 컴퓨터에게 이미지는 숫자들의 나열 그 이상도 그 이하도 아니기 때문이죠. 흑백 사진인 gray scaled image같은 경우는 정말 단순한 2D matrix 이며, color image의 경우에는 3D tensor가 됩니다. 아래와 같이 말이죠.
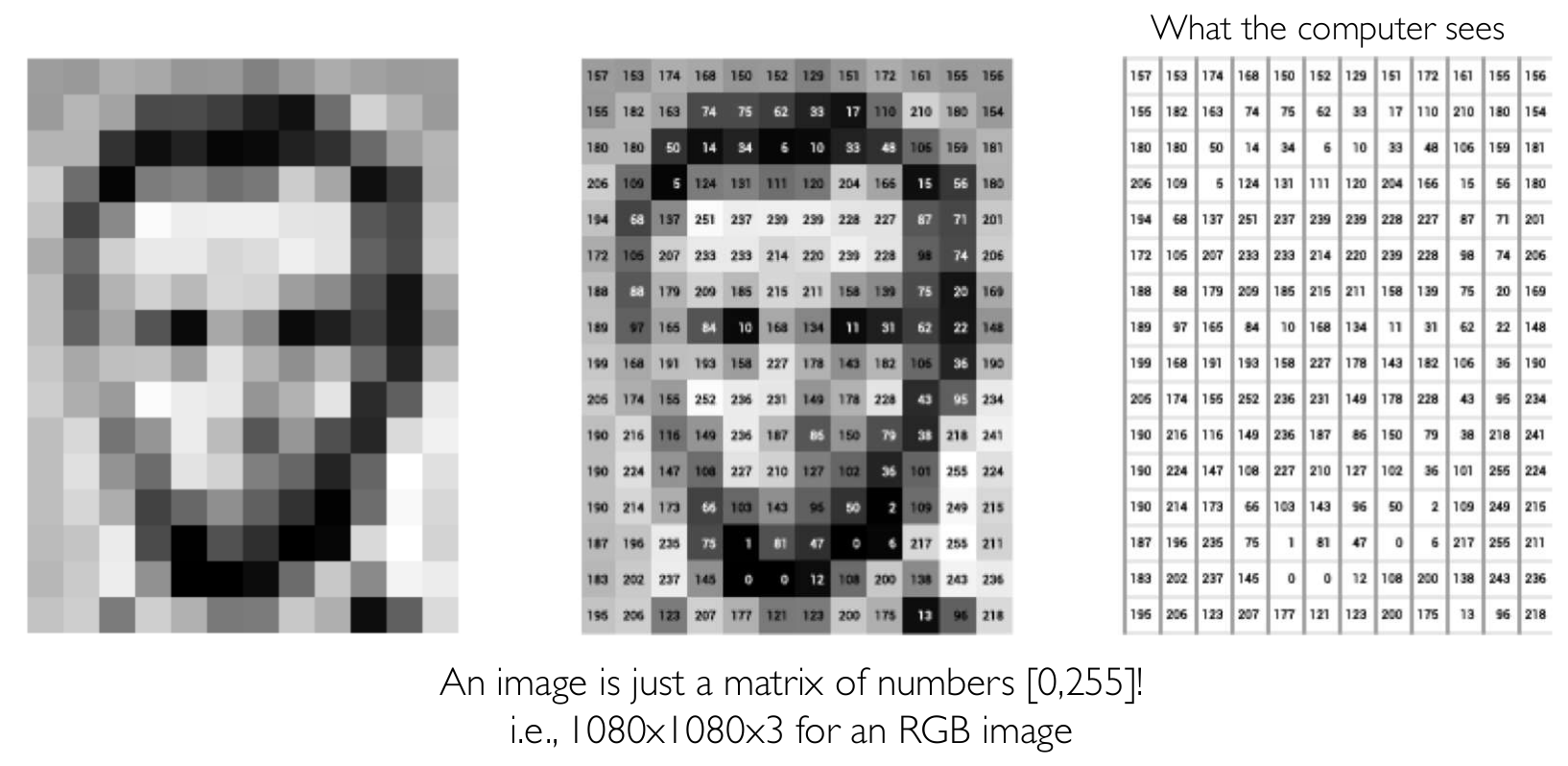
이번 강의는 이러한 이미지를 computer가 보다 잘 분류할 수 있는 Convolutional Neural Network에 대해서 소개하고 있습니다.
Tasks in Computer Vision
Vision domain에서 가장 대표적인 task는 classification입니다. 모델이 input image를 받아서 pattern을 추출한 뒤 해당 pattern이 어떤 class (category)인지를 예측하는 task를 분류라고 합니다. 이러한 분류 문제를 잘 해결하기 위해서는 모델이 각 class의 특징적인 properties를 파악하는 능력이 있어야 할 것입니다. 예를 들어 사람과 자동차를 분류하기 위해서 모델은 사람이 가지고 있는 형태 (edges), 눈, 코, 입과 같은 특징 (feature)를 잘 파악해야 하며 자동차의 edge, 창문, 바퀴과 같은 특징도 잘 파악해야 합니다.
이러한 분류 문제를 풀기 위하여 전통적으로 feature를 manually 추출 하였습니다. 물론 성능이 좋고 지금까지도 여러 분야에서 쓰이는 hand-crafted feature 방식들이 있지만 이러한 방식에서는 occlusion, deformation, illumination과 같은 이미지의 variation에 강건하지 못한 치명적인 한계가 있습니다. 다시 말해, 동일한 class임에도 불구하고 이미지의 단순한 shifting에도 분류 정확도가 매우 떨어지는 문제를 지니죠. 아래는 여러 이미지 variation에 대한 예제 입니다.

그렇다면 이러한 한계를 어떻게 해결할 수 있을까요? 이에 대해서 연구자들이 내린 답은 classifier (model)에게 직접 중요한 feature를 추출하도록 하면 해결되지 않을까? 였습니다.
Learning Visual Features
Fully Connected Neural Network (FCN)
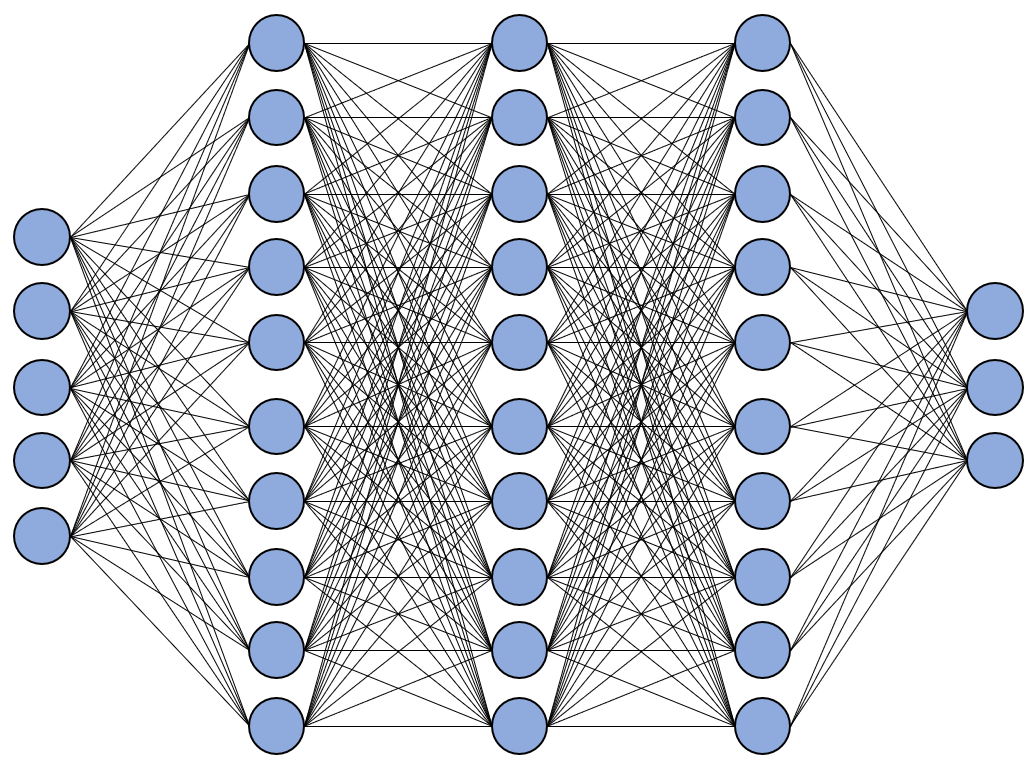
위의 이미지에 보이는 구조가 fully connected neural network입니다. FCN는 위에서 보이는 것처럼 모든 neuron이 연결되어 있는 구조입니다. 하지만 FCN은 input image의 위치 정보를 보존할 수 없으며 update해야할 parameter가 매우 많다는 단점이 있습니다.
그렇다면 어떻게 input의 위치 정보를 network에서 사용할 수 있을까요?
Using Spatial Structure
아이디어는 이렇습니다. FCN처럼 모든 layer의 neuron을 연결하는 것이 아니라 filter를 사용하여 특정 patch만 연결하자. 그런 다음 sliding window라는 개념을 통해서 마치 layer 전체가 연결되는 효과를 가져옵니다. 여기서 filter는 set of weights입니다. 즉 모델의 weights들의 집합인 것이죠.
Applying Filters (set of weights)
- Filter는 input image 혹은 이전 layer의 local featrues를 추출하기 위하여 사용합니다.
- 또한 다양한 종류의 featrues를 추출하기 위하여 여러개의 filter를 사용해야 합니다.
- 각 filter는 weight를 공유합니다.
Feature Extraction with Convolution
만약 filter의 크기가 3x3의 matrix라면 한 filter에 9개의 weight가 있음을 의미합니다. 이 3x3 filter를 stride만큼 옮겨가면서 input image에 적용하게 됩니다.
이러한 연산을 Convolution이라 부릅니다.
아래 gif를 확인해보죠.
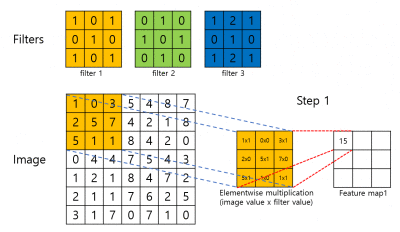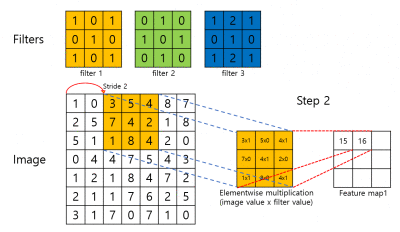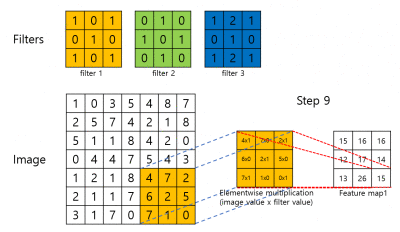
위의 gif는 3x3 filter가 stride 2인 경우 어떻게 연산이 되는지를 보여줍니다. 순서는 다음과 같습니다. Input image에 pixel값과 filter의 weight 값이 elementwise 곱해집니다. 그 후 연산된 값들을 모두 더 해 feature map의 한 pixel값이 됩니다. Filter는 stride의 크기만큼 image (feature map)을 건너띄며 convolution 연산을 진행합니다. 첫 번째 filter가 image (feature map) 전체에 대한 연산을 마무리 하면 두 번째 filter가, 그 후에는 또 그 다음 filter가 순차적으로 convolution 연산을 진행합니다. 최종적으로 하나의 filter마다 하나의 feature map이 생성되게 됩니다.
Feature Extraction and Convolution A Case Study
그렇다면 이러한 방식은 hand-crafted feature들에 비해 장점을 가질까요?
수업에서 제시하는 예시는 다음과 같습니다. 사람은 아래 두 이미지 모두 x로 판단하겠죠.
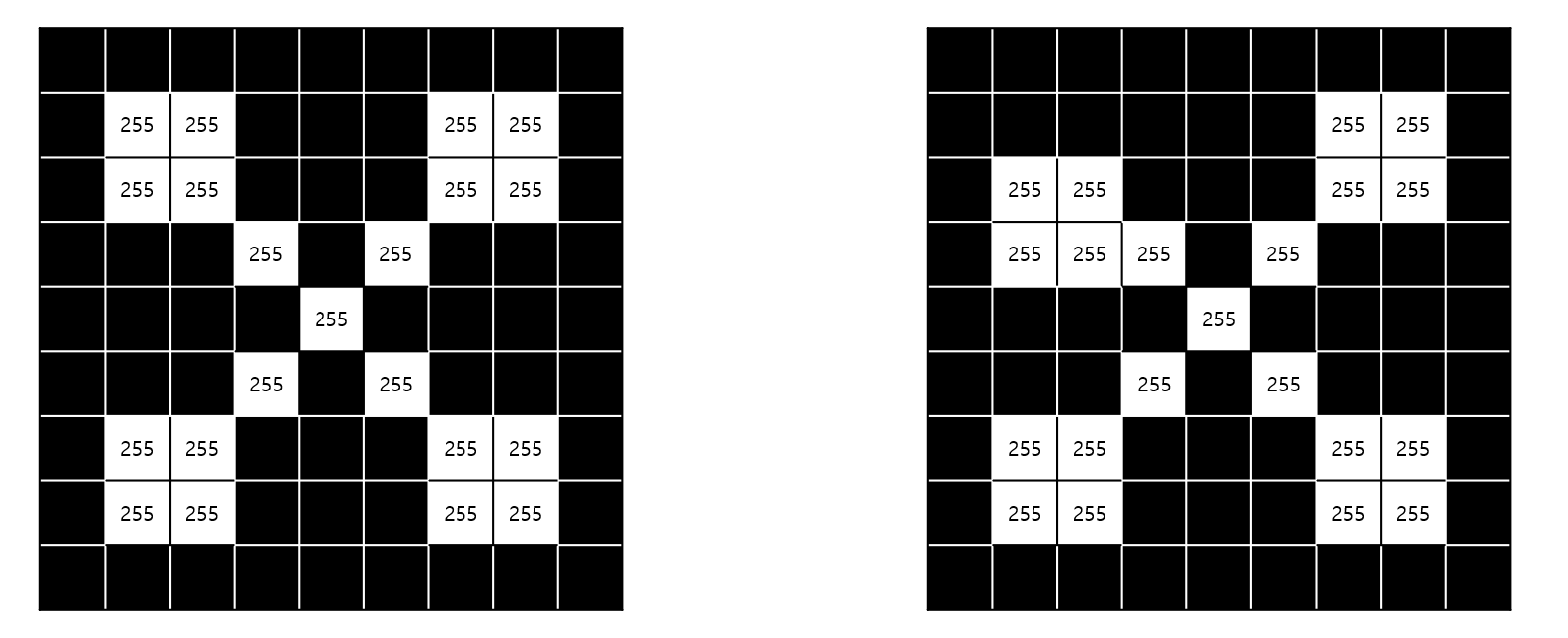
하지만 기존의 방식으로는 이러한 variation에 강건하기 힘듭니다.하지만 우리는 shited, shrunk, rotated, deformed와 같은 variation에대해 모델이 강건하기를 바라며 이러한 이유로 convolution 연산을 사용합니다.
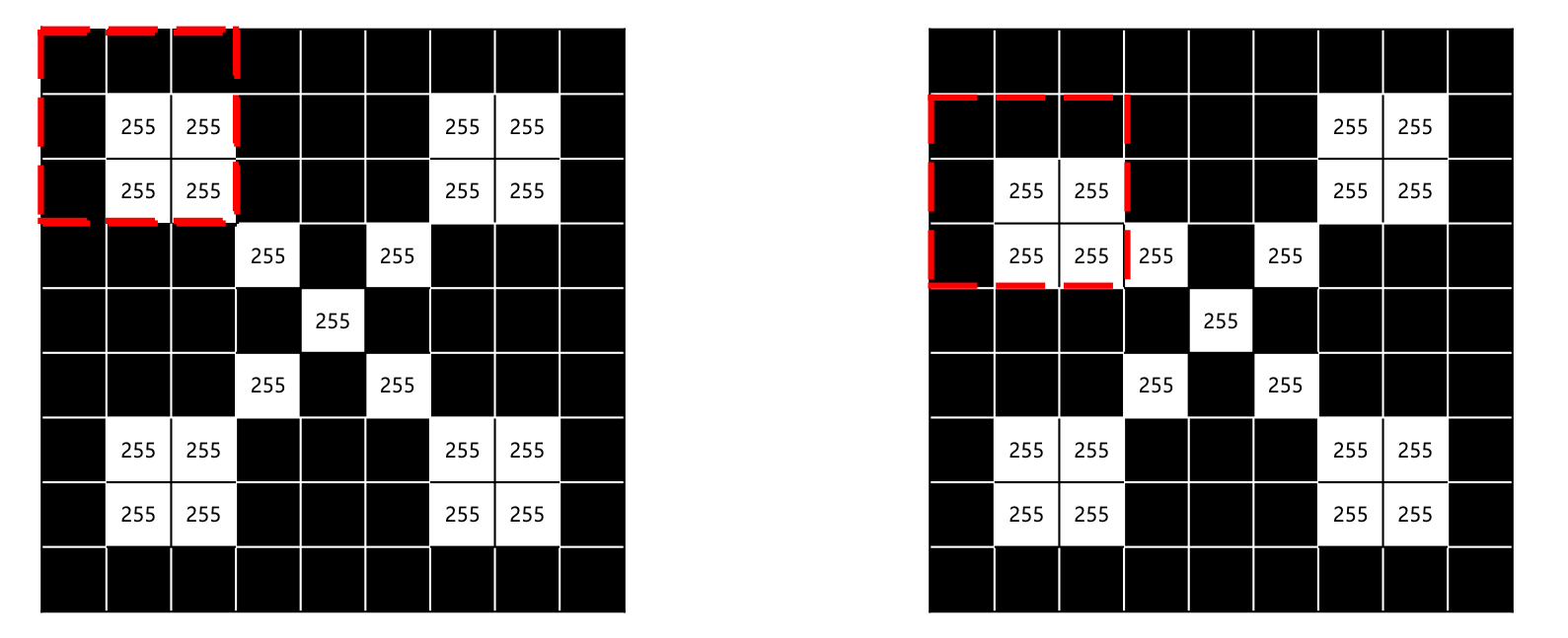
위의 figure와 같이 3x3 filter가 stride 1로 움직이며 연산을 하다보면 왜곡된 이미지임에도 불구하고 동일한 featrue를 강건하게 추출할 수 있게 됩니다.
Convolutional Neural Networks (CNNs)
CNN은 아래와 같은 propertise를 가집니다.
- convolution : Feature map을 생성하기 위해서 학습된 weights로 이루어진 filter를 적용하여 convolution 연산을 진행
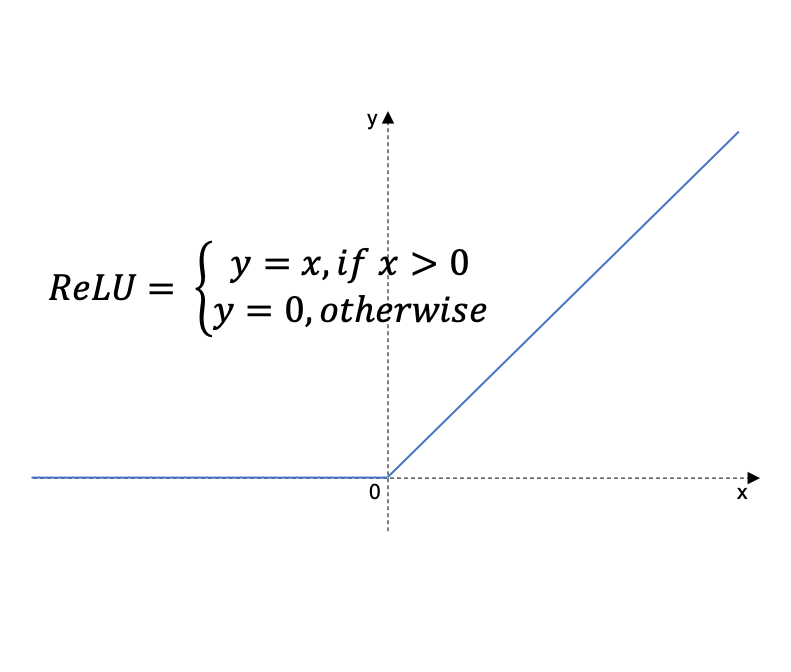
- Non-linearity : Convolution 연산 이후에 비선형성을 추가해주기 위한 activation function 진행(일반적으로 ReLU-아래 figure 참조) 사용
- Pooling : 각 feature map에 downsampling 진행(max나 average pooling)
Receptive field
Receptive field는 레이어의 각 뉴런이 입력 볼륨의에 연결된 로컬한 영역(local region)을 의미합니다. 결국 filter와 같은 의미가 되겠죠.
Stride가 1인 경우 receptive field 상 넓은 영역이 겹치게 되고, feature map의 크기도 매우 커지게 됩니다. 반대로, 큰 stride를 사용한다면 receptive field끼리 좁은 영역만 겹치게 되고 feature map의 크기도 작아지게 되겠죠.
Class Probabilities
Convolution layers와 pooling layers는 input image의 high-level features를 추출합니다.
- Fully connected layer는 상기 features를 사용하여 input image의 class를 분류하는 역할을 맡습니다.
- 분류의 경우 softmax를 사용하여 input image가 특성 class에 속할 확률을 확률적으로 표현해 줍니다.
Backpropagation
CNN은 수 많은 filter의 weights와 fully connected layers (dense layers)의 weights를 업데이트 하기 위하여 역전파를 시행합니다.
마무리
강의에서는 CNN 구조를 분류 뿐만 아니라 segmentation, object detection, 안면 인식, 자율주행 차와 같이 다양한 분야에서 사용하고 있음을 말하고 있습니다. 물론 어느날 본질적으로 더욱 사람에 가까운, 지금 CNN이 가진 문제들을 해결해주는 brand new architecture가 등장하겠으나 현재는 또 꽤나 오랜 시간 CNN은 범용적인 domain에서 좋은 성능을 보일 것 같습니다.
수업을 듣다보니 아무래도 대상이 1학년 생들이라서 그런지 내용이 굉장히 얕더군요. 큰 그림만 잡아간다는 생각으로 편하게 보시기 좋은 포스팅이 된 것 같습니다!
Leave a comment