An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (ViT)
ICLR 2021에 “AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE” 라는 제목을 가진 논문이 게재되었습니다. Google research와 brain에서 힘을 합쳐 진행한 연구인데요, 역시 구글입니다. 폭발적인 후속 연구들을 이끈 논문, ViT에 대해 알아보겠습니다.
Transformer
Transformer 구조는 NLP domain에서 이미 지배적입니다. 일반적으로는 wikipedia와 같은 대용량의 corpus를 통하여 pre-train을 시킨 후 target domain의 data를 통하여 further pre-train을 진행합니다. 사실 further pre-train 단계는 optional한 감이 있지만 가능한 상황이라면 진행하는 것이 좋다로 정리가 되는 것 같습니다. 이후 최종적으로 task-specific dataset을 통하여 fine-tuning을 진행합니다. 현재 NLP는 BERT 전성시대 라고 불러도 과언이 아닙니다. 이러한 BERT와 지속적으로 후속 모델을 내고 있는 GPT 시리즈는 Transformer를 기반하고 있습니다. 결국, Transformer를 통해 seq2seq-based model의 한계들을 극복하여 모든 downstream task에서 SotA를 기록하고 있다고 볼 수 있습니다. 오늘 소개할 ViT는 Transformer를 vision에서 사용할 수 없을까? 라는 고민에서 시작되었습니다.
ViT
Model structure
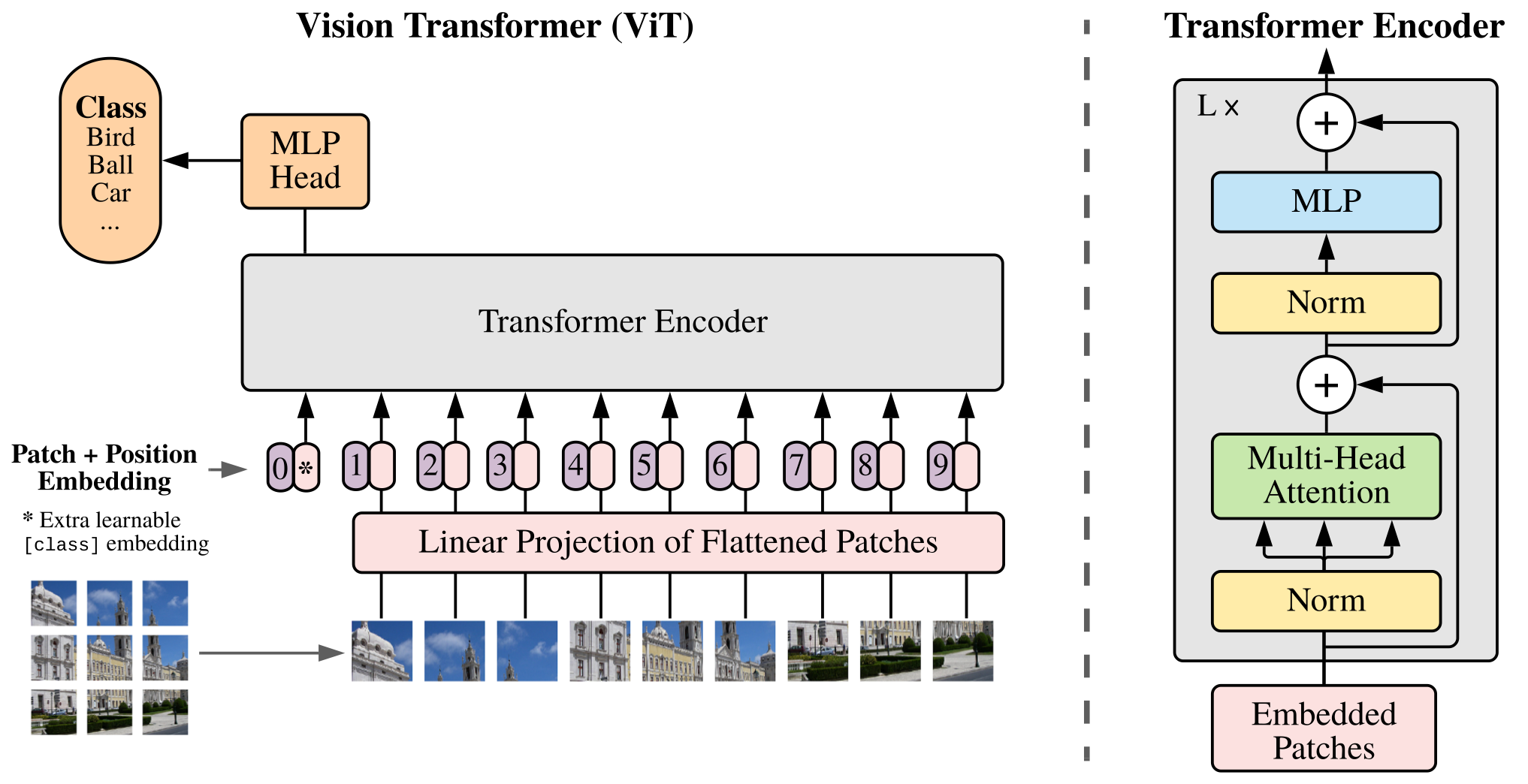
ViT의 구조는 Figure 1과 같습니다. 매우 단순합니다. Transformer를 알고 계신 분이라면 추가적으로 이해를 해야하는 부분이 거의 없습니다. Transformer에 익숙하지 않으신 분들은 본 블로그를 참고해 주세요.
Image to patch
ViT는 Transformer에 image를 feeding합니다. 일반적인 상황에서는 Transformer에 문장이 들어가죠. 전처리를 진행한 후 [“나”, “너”, “사랑”] 이라는 word token들이 input으로 들어가면, Transformer는 [“I”, “Love”, “You”]라는 token들로 구성된 output을 내뱉습니다. 결국 이미지 한 장을 한 문장으로 고려할때 우리는 저 문장 내부의 단어, 즉 token을 어떤식으로 구성해야 할 지를 해결해야 합니다. 본 논문에서 저자들은 이미지를 자르는 형태로 이를 해결합니다. 사실 이미지를 patch로 잘라 전처리를 진행하거나 model에 input으로 사용하는 연구들은 이전에도 많았습니다(역시 아는 것이 힘입니다). Figure 1의 <Linear Projection of Flattened Patches> 아래에 보면 작은 사이즈의 이미지들이 나열되어 있는 것을 볼 수 있습니다. 여기가 이미지를 patch로 잘라 한 patch를 하나의 token으로 사용함을 보여주는 부분입니다. Patch의 사이즈는 원본 이미지가 $x \in \mathbb{R}^{H\times W\times C}$ 인 경우에 $x_p \in \mathbb{R}^{N\times (P^2\times C)}$ 로 정해집니다. 예를 들어 9x9 크기의 color image가 있을 때, patch size를 3으로 지정하면 3x3 ($P^2$) patch가 9 ($N$)개 생성되겠죠. 그럼 이 9 개의 patch를 token으로 고려해서 vector로 만든 후에 <Linear Projection of Flattened Patches> module에 넣어주게 됩니다. 비록 image는 word token과 다르게 연속적이지만, 모델이 보다 의미 있는 input을 받게 하기 위해서 embedding을 거칩니다.
다만 한 가지 “실험적으로” 주의 하실 점은, patch를 vector로 만드는 부분입니다. 일반적으로 flatten을 한다고 생각하기 쉽고, 몇몇 공개된 ViT code에서도 flatten을 사용하고 있으나 모델의 성능을 위해서 kernel size와 stride가 patch size이며 output dim이 vector size로 지정된 Conv2d를 사용해야 합니다. 위의 예시와 같은 상황에서는 아래와 같이 지정된 kernel을 통하여 각 patch를 256차원의 vector로 변경할 수 있습니다:
torch.nn.Conv2d(3, out_channels=256, kernel_size=3, stride=3)
Position Embedding
다음으로 구성해야하는 input은 Position embedding 입니다. 이는 input patch의 위치를 모델이 알 수 있게끔 해주는 역할을 합니다.
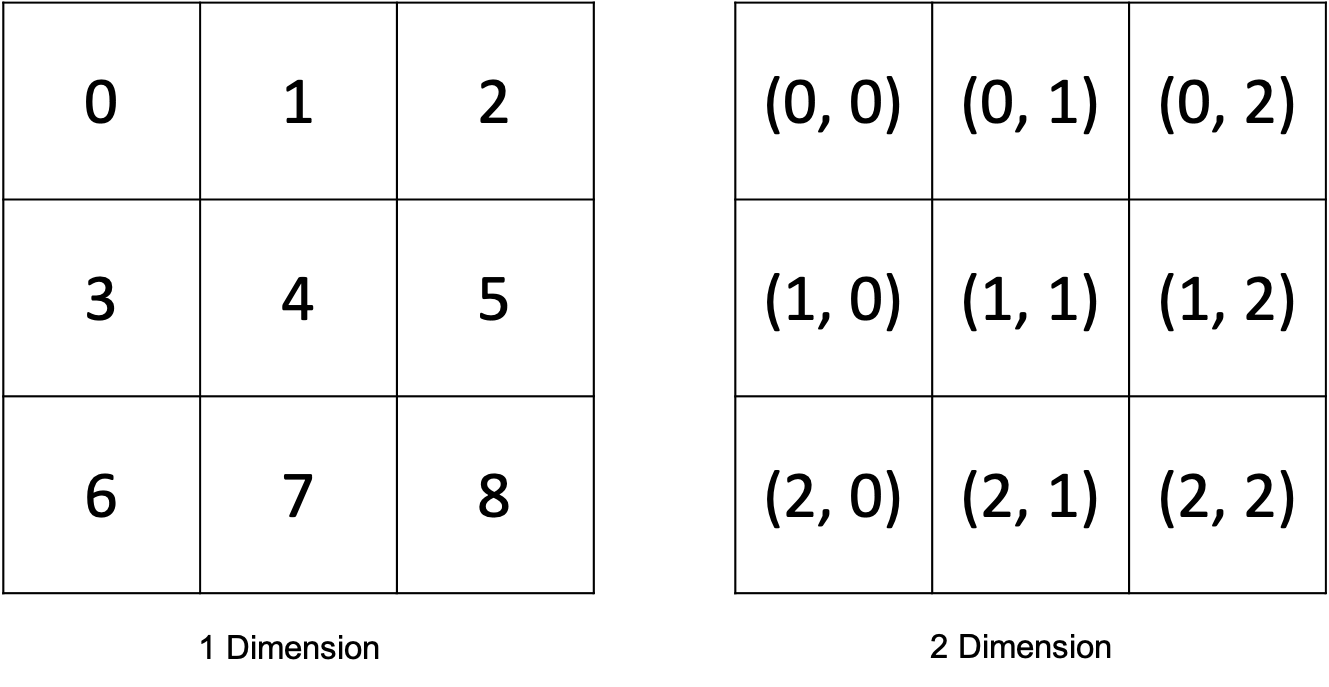
위의 Figure 2에서 볼 수 있듯이 이미지를 대상으로 하는 position embedding은 1차원, 혹은 2차원으로 구성할 수 있습니다. 본 논문에서는 두 가지 모두 사용해본 결과 성능에는 큰 차이가 없다고 말합니다. ViT position embedding의 특징은 Figure 2와 같이 patch의 실질적인 위치를 사용하거나 Transformer의 position embedding처럼 계산에 의한 값을 사용하지 않는다는 것 입니다. ViT의 position embedding은 random하게 초기화 되어 모델의 학습이 진행되는 동안 지속적으로 update 됩니다. PyTorch에서는 torch.nn.Parameter() 로 지정됩니다.
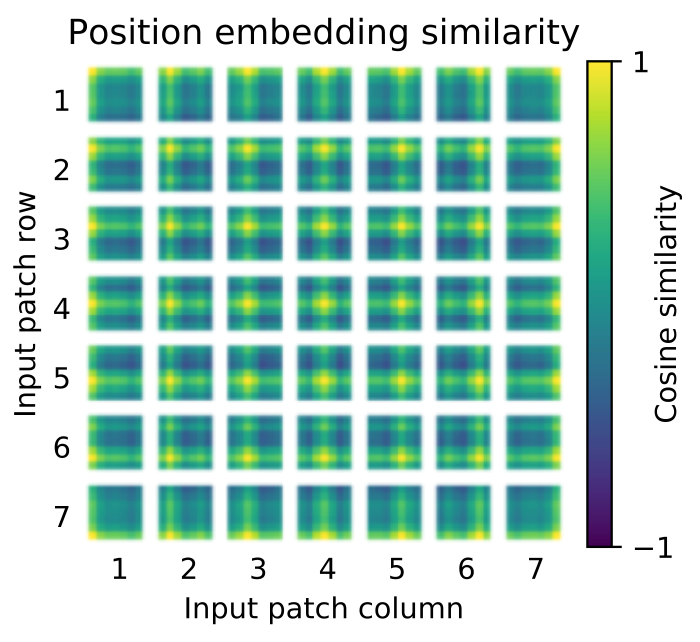
Figure 3를 통해 논문에서 제시하는 position embedding 끼리의 유사도를 확인할 수 있습니다. 밝은색일수록 유사하다는 의미이며 반대로 짙은 초록색일수록 유사성이 떨어진다는 의미 입니다. Random vector로 초기화 되어 학습이 된 ViT의 position embedding은 신기하게도 같은 행과 열의 embedding들과 유사성이 높음을 확인할 수 있습니다. 이런식으로 구성되는 position embedding은 linear layer를 거친 image patch vector와 더해져서 Transformer module의 input으로 사용됩니다.
추가적으로 ViT에서는 NLP의 Transformer의 문장을 대표하는 CLS token과 같은 역할을 하는 $z_0$ token을 사용하여 이미지를 대표하도록 합니다.
Inductive Bias
최근 한 커뮤니티에서 논의가 활발했던 inductive bias에 대해 살펴보겠습니다. Inductive bias에 대한 본 포스팅의 해석은 지극히 개인적인 의견이니 참고만 하시길 부탁드립니다.
개인적으로 inductive bias를 engineer가 임의로 주는 편향으로 정의하고 있습니다. 본 논문의 저자들의 주장을 바탕으로 예를 들어 보자면, CNN의 경우에는 input image에 비해 매우 작은 size의 kernel을 사용함으로써 receptive field를 local에서 global로 가져가게끔 engineer가 의도 했다고 해석할 수 있습니다. 결국 이러한 의도로 CNN은 locality라는 inductive bias가 강하게 생기게 되는 것이죠. 하지만 ViT에서는 self attention layer가 global하게 연산되기 때문에 inductive bias가 없다고 저자들이 주장하고 있습니다. 이러한 주장이 나오게 되는 배경을 살펴보면 지금까지 충분한 양으로 생각 됐던 ImageNet-1k dataset으로 모델을 학습하는 경우 ResNet에 비해 성능이 좋지 않았기 때문입니다. 이러한 좋지 못한 결과에 타당성을 부여하기 위해 ResNet은 locality라는 inductive bias에 의해 강하게 drive되는 모델이기 때문에 적은 양의 데이터로 학습을 진행해도 좋은 성능을 보일 수 있지만, ViT의 경우에는 그러한 inductive bias가 없기 때문에 NLP의 wikipedia dataset과 같은 대용량의 데이터(ImageNet-21k, JFT-300M)가 필요하다고 주장합니다.
하지만 이러한 주장은 말 그대로 본인들의 실험 결과를 납득시키기 위한 주장이지 않을까 생각합니다. 우선 최근 연구들을 살펴보면 regularization과 augmentation을 통해서 ImageNet-1k로도 학습이 가능하다는 논문 “How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers”도 등장하였으며, ViT에서도 position embedding이라는 locality information을 담고 있는 vector를 통해 bias를 주고 있습니다. 또한 우리가 CNN을 사용하는 동안 locality라는 inductive bias를 고려한 적이 없었던 것 처럼 또 다른 모델이 Transformer를 대체한다면 ViT의 global한 attention 연산 또한 inductive bias로 해석될 수 있지 않을까? 싶습니다. 이러한 생각에 의해 ViT를 inductive bias가 없는 모델이다 라고 말하기에는 틀렸다는 느낌이 있습니다. 그저 locality에 관련된 inductive bias가 CNN에 비해 작은 모델이라고 보는 게 정확하지 않을까 싶습니다.
Experiments

Table 1에는 ViT paper에서 사용한 모델들에 대한 설명을 확인할 수 있습니다.
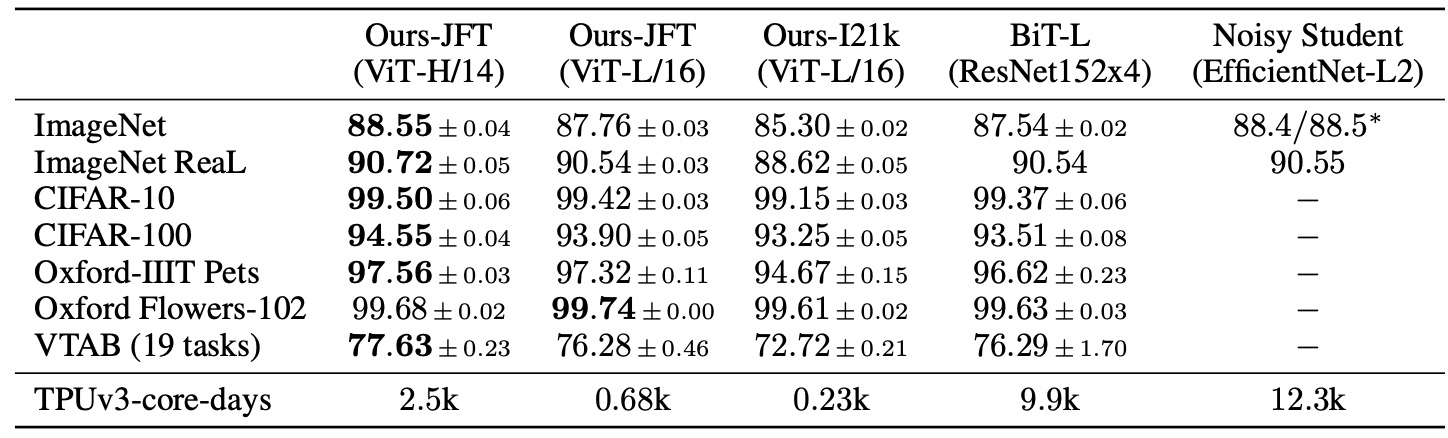
Table 2를 확인해보면 확실히 JFT-300M dataset으로 ViT를 pre-train한 경우에 성능이 가장 좋음을 확인할 수 있습니다. ImageNet-21k는 앞선 설명과는 다르게 large dataset 임에도 불구하고 ResNet에 비해 좋은 성능을 못 보여주고 있습니다.
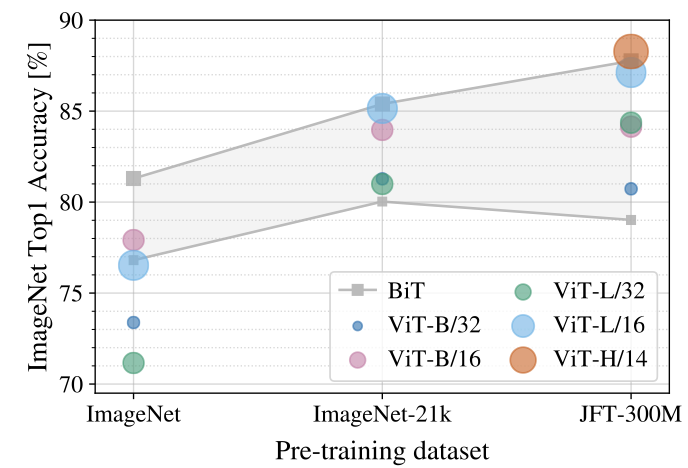
Figure 4에서는 pre-train dataset에 대한 ImageNet-1k의 top-1 accuracy를 보여주고 있습니다. BiT는 ResNet에서 Batch Norm을 Group Norm으로 변경하고, standardized convolutions를 사용한 모델입니다. 결과를 살펴보면 volume이 작은 dataset으로 pre-train을 진행하는 경우에는 ViT에 비해 BiT가 좋은 성능을 보이고 있지만 JFT-300M으로 pre-train을 진행하면 ViT가 더 좋은 성능을 보이게 됩니다.
지금까지 ViT에 대해서 간략하게 리뷰를 진행했습니다. AlexNet의 등장 이후로 ResNet-based model들까지 굉장히 빠르게 발전했던 것처럼, 수 없이 많은 발전된 ViT-based model들이 등장하지 않을까 싶습니다. 이미 굉장히 활발하게 연구가 진행되고 있구요! 천천히 하나씩 리뷰를 진행해보겠습니다.
Leave a comment