Introduction to Deep Learning-MIT 6.S191
AGENDA
1. Introduction of basic concepts for Deep learning
이미 너무 유명하고 우리에게 친숙한 Stanford 에서 제공하는 CS231n 수업 외에도 deep learning을 학습하기 위한 좋은 material이 있지 않을까? 라는 생각에서 시작하여 2019년 MIT에서 제공하는 deep learning 수업을 review 해볼까 합니다. 전반적으로 CS231n보다 범위가 넓고 깊이가 얕은 특성이 있는 듯 합니다.
사족이지만 해당 class의 final project의 결과에 따라 우수한 학생에게는 RTX 2080 Ti를 상으로 제공한다고 하네요…. MIT 만세
Deep learning은 무엇인가?
“An intelligence as the ability to process information to inform future decision.”
수업 진행자가 하는 말을 그대로 가지고 와보았습니다. 이는 결국 데이터의 패턴을 잘 파악하여 미래 데이터에 적용한 후 정보를 추출하는 일련의 과정이 됩니다. 그렇다면 어떠한 점들이 machine learning과의 차이점일까요?
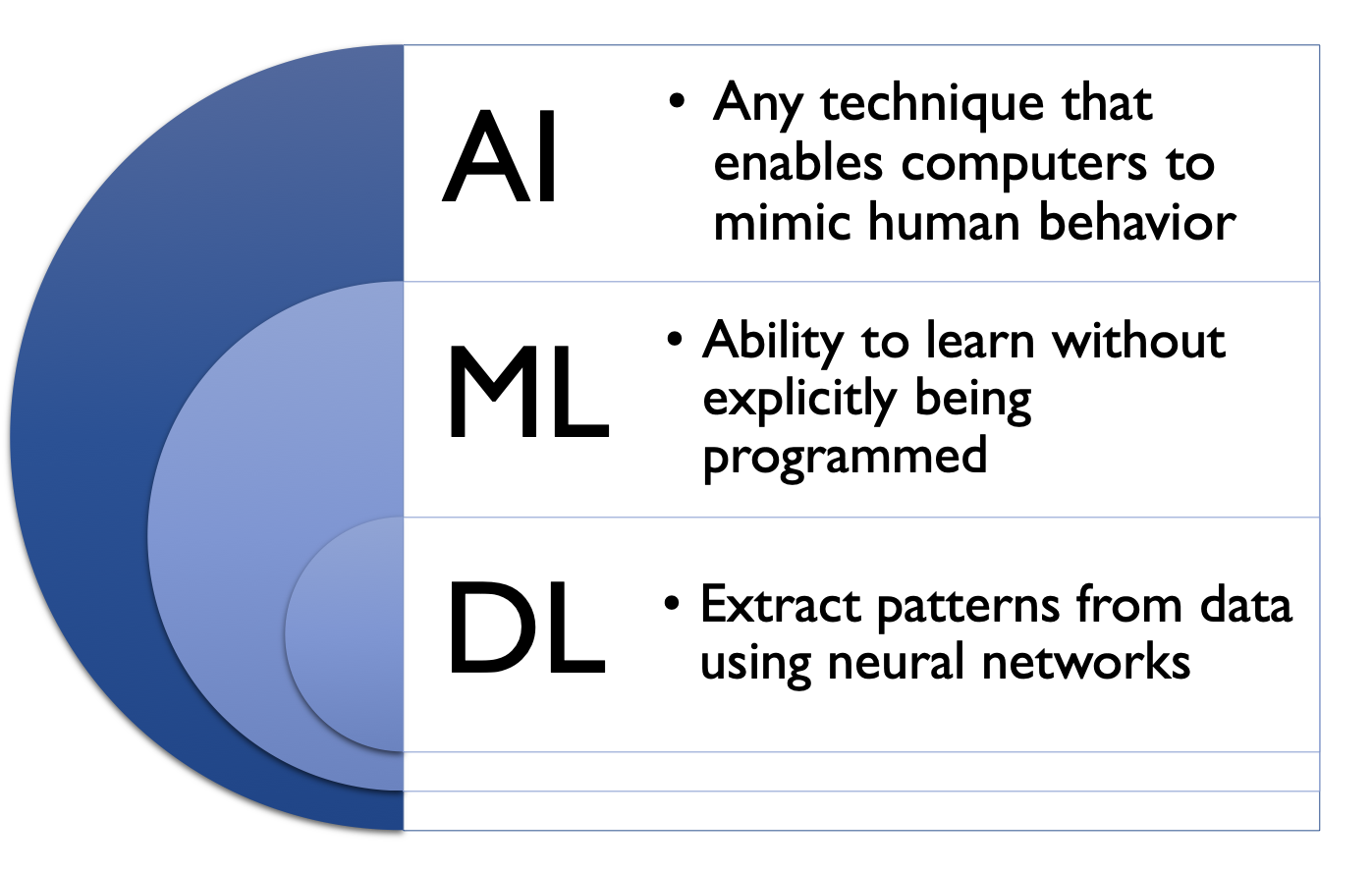
위의 그림은 Artificial intelligence (AI), machine learning (ML), 그리고 deep learning (DL)의 차이를 나타내고 있습니다. AI가 가장 큰 범위의 개념으로 기계가 사람과 같이 행동할 수 있는 모든 기술을 의미하고 있으며 ML은 AI에 속하는 개념으로 어느정도 자동화가 되어 학습된 패턴을 통하여 미래 데이터에 대하여 의사결정을 내리는 행위를 의미합니다. 마지막으로 최근 비약적인 속도로 발전하고 있는 DL분야는 ML에 속하는 굉장히 좁은 영역으로 ML에 비해 사람의 손을 덜 타는, 예를 들어 image domain에서 이미지를 잘 표현하기 위하여 여러 방법으로 hand-crafted features를 추출하는 것이 기존 ML의 중요한 이슈였다면 deep learning에서는 모델이 알아서 feature를 뽑도록 합니다, 보다 지능적인 프로세스 라고 표현할 수 있을 것 같습니다.
그렇다면 우리는 왜 deep learning을 해야 할까요?
가장 단순하게 이야기 하면 기존에 사용하던 hand-crafed features에 비하여 우리의 손을 거치지 않고 기계가 직접 중요하다고 판단한 features를 사용하는 것이 많은 분야에서 성능이 ‘훨씬’ 더 좋기 때문일 것입니다.
Feed forward propagation
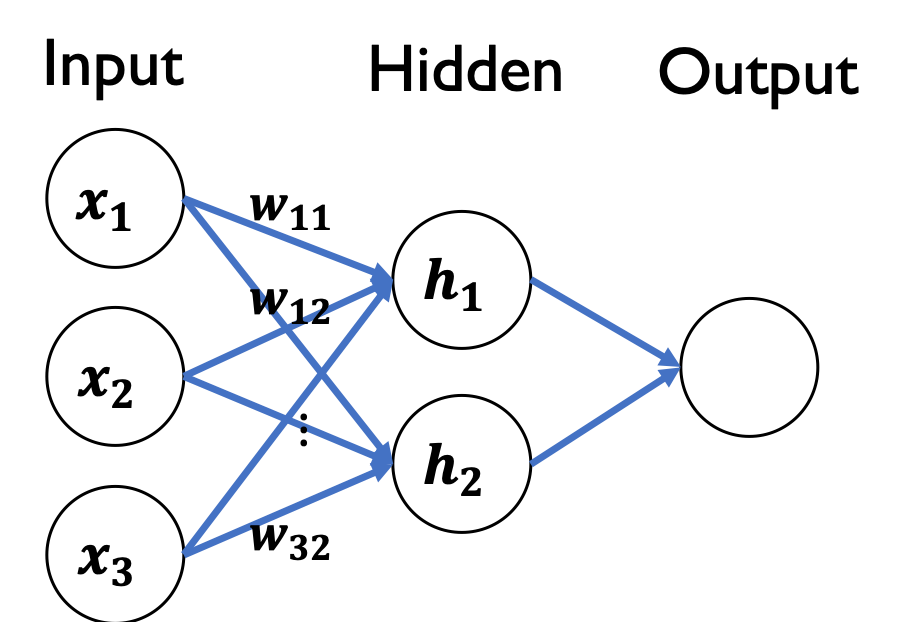
일반적인 neural network의 feed forward propagation은 위 그림에서 보이는 \(x_1, x_2, x_3\)와 같은 input들과 \(w_11, w_12, w_32\)와 같은 weight들의 dot product 로 나온 값을 비선형 함수에 input으로 사용하는 과정들을 반복한 후 최종 output이 산출 됩니다. 이 과정에서 추가되는 bias term은 activation function을 shift하는 효과를 준다고 하네요.
Neural network는 사실 Fig 2.에서 가운데 위치하는 hidden layer를 여려층 쌓음으로 매우 복잡한 결합함수 형태를 가집니다. 만약 선형함수를 계속 결합한다면 어떻게 될까요? 최종적인 함수의 형태도 선형 함수가 되겠죠? 그렇다면 힘들게 쌓아올린 hidden layer들이 큰 의미를 갖기 어려울 것입니다. 이러한 문제를 해결하기 위하여 neural network에서는 비선형함수인 activation function을 사용하여 모델에 비선형성을 추가해 줍니다. 이러한 특성 덕분에 neural net은 매우 비선형적인 현실 데이터에서도 높은 성능을 지닐 수 있게 됩니다.
가장 유명하고 오래 쓰인 activation function은 sigmoid 함수 입니다. sigmoid 함수는 인풋을 0-1로 바꾸어주기 때문에 모델을 통하여 확률을 구하고자 하는 경우에 상당히 유용한 함수가 될것이라고 강의자는 말하고 있습니다. 또 하나의 유용하고 유명한 함수는 Rectified Liner Unit (ReLU) 입니다. ReLU의 경우 0보다 작은 input은 무시하고 0보다 큰 값에 대하여서는 인풋이 아웃풋이 되는 \(y=x\) 형태를 띄고 있습니다. 이러한 특성 때문에 picewise linearity라고 불리죠. 이렇게 단순한 함수로 충분한지 의심이 드실텐데요, ReLU는 굉장히 선형적으로 생겼음에도 불구하고 모든 중요한 속성을 보존함과 동시에 연산이 쉽기 때문에 최근 대부분의 모델에서 사용하고 있습니다.
Building neural network with Perceptrons
그림 2에서 \(h_1\)은 inputs과 weights를 사용한 weighted sum 형태가 됩니다. 이렇게 weighted sum이 된 값에 activation function을 거쳐 neuron 하나의 output이 산출되죠. Hidden unit이 많아져도 neuron마다 찬찬히 살펴보면 단순히 하나의 neuron을 가진 perceptron network (그림 2) 와 다를바가 없습니다. 물론 weights들의 값이 다르기 때문에 \(h1, h2\)의 값은 각각 다르겠지요. 이렇게 빽빽하게 weight가 연결된 구조를 우리는 dense layer라고 부릅니다. Deep Neural Network또한 이러한 구조와 크게 다르지 않은데, 단순히 계속적으로 엄청 많이 계속 계속 이러한 dense layer을 stack하게 되면 그것이 DNN이 됩니다.
Applying Neural Networks
굉장히 뜨겁고 모든 것을 해줄것만 같은 deep learning model또한 물론 만능이 아닙니다. 사람이 봤을때도 합리적인 판단을 모델이 하기 위해서 우리는 모델을 ‘잘’ 학습 시켜야만 하죠. 우리는 실제 정답을 ground truth, model이 예측한 정답을 predicted output이라 부르며 이 둘의 차이를 점차 줄여나가는 과정을 학습이라 부릅니다. 이처럼 실제 정답과 모델이 추측한 정답을 줄여나가기 위하여 세우는 함수인 Loss function (NLL, cross-entrophy, MSE와 같은 다양한 방법들이 있습니다)을 정의하는 것은 machine learning의 art에 속합니다.
Training Neural Networks
위에서 우리는 모델을 잘 학습 시켜야 한다고 말하였습니다. 그렇다면 학습을 시킨다는 것은 무엇을 의미하는 것일까요? 모델을 학습 시키는 궁극적인 목표는 모델이 가지고 있는 파라미터 W (weights)를 최적화 하는 것입니다. 여기서 최적화의 의미는 predicted output과 ground truth의 차이를 최소화 하는 것이 됩니다. 하지만 Neural network는 위에서 말한 것 처럼 상당히 많은 layer (function)가 stack되어 있기 때문에 최적해를 closed form으로 구할 수 없는 문제점을 가지고 있습니다. 이러한 어려운 상황에서 해를 구하기 위해서 우리는 gradient descent와 backpropagation을 사용합니다.
Neural Networks in practice
Optimization
DNN은 매우 복잡한 결합함수 형태를 띄고 있기 때문에 구조적으로 매우 많은 local minimum이 존재하고 initial point에 따라 이런 local minimum에 빠질수도, 저런 local minimum에 빠질 수도 있습니다.
이 때문에 optimization (adam, adadelta, RMSprop, …) 연구도 매우 활발히 진행 되었으나 최근에는 주춤하는 모습인것 같습니다. 본인이 선호하는 optimizer를 사용하는 추세이며 ‘local optimum에 빠지더라도 충분히 좋다’ 라는게 학계의 정설 입니다.
Overfitting
Model은 새로운 데이터 (test set)에 대해서도 강건함을 목표로 학습됩니다. 다시 말해, 처음 보는 데이터에 대해서도 학습때의 성능을 보여주길 바라며 모델을 학습 시키죠. 하지만 간혹 학습 데이터를 완전히 외워버리는 모델들이 등장하곤 하는데 이러한 경우 새로운 데이터에 대한 성능은 현저히 떨어질 수 밖에 없습니다. 학습 데이터를 온전히 외워버리기 때문에 새로운 데이터에 대해서 대처하지 못하는 상황이기 때문이죠. 이러한 현상을 우리는 overfitting이라 부릅니다.
Regulaization
이러한 overfitting 현상을 완화하기 위하여 사용하는 방법이 regularization입니다. 가장 유명하고 널리 사용되는 방법은 dropout으로 특정 neuron을 deactivation 시키는 방식입니다. 이러한 방식을 통하여 모델이 특정 witght에 온전히 의존하지 못하게 하는 것이죠.
두 번째 방식은 early stopping이라 불리는 트릭 입니다. 이름과 같이 말 그대로 빠르게 학습을 중단시키는 방식인데 그 기준은 training error는 계속 낮아지지만 validation error가 올라가는 지점입니다. Training set은 학습에 계속 사용 되지만 validation set은 학습에 사용되지 않기 때문에 validation error가 올라간다는 것은 모델이 overfitting되어 test set의 performance도 떨어질 것이라는 가정을 담고 있는 것이죠.
마무리
기본적인 컨셉을 잡는 강의었습니다. 구글이나 유튜브에 ‘MIT 6.S191’를 검색하시면 슬라이드와 강의 영상을 쉽게 찾으실 수 있으니 관심 있으신 분들은 꼭 본 강의를 참고 부탁드립니다!
Leave a comment