Deep learning을 속이는 기술: Adverarial example (paper: Explaining and Harnessing Adversarial Examples)
AGENDA
1. What are the adversarial examples
2. Explaining and Harnessing Adversarial Examples 논문 설명
Adversarial example에 대하여 생소하신 분들이 있으실 수 있으니, 우선 간략히 해당 개념에 대하여 영상과 함께 설명 드리겠습니다. 그 후 본 포스트의 주제인 Explaining and Harnessing Adversarial Examples 논문에 대하여 설명 드리겠습니다.
Adversarial example이란 무엇인가?
위의 영상을 보시면 바나나가 있습니다. 바나나가 홀로 있을 때와, 영상 초반에 깨끗해 보이는 이미지 패치 (사람이 들고 있는 작은 이미지)를 바나나 옆에 두었을 때는 학습해둔 모델이 100%에 가까운 confidence로 바나나를 분류 하고 있습니다(초록색 그래프). 하지만 영상 중반부에 나오는 이상하게 생긴 이미지 패치를 바나나 옆에 두게 되면 모델은 이전과 다르게 100%에 가까운 confidence로 바나나를 토스터기로 오분류 하고 있음을 볼 수 있죠. 이와 같이 모델이 오분류를 하게끔 하는 패치를 “Adversarial patch”, 모델이 오분류를 하게끔 noise를 더한 이미지를 adversarial example이라 부릅니다.
Adversarial example의 통상적인 정의는 아래와 같습니다:
Original input에 매우 작은 noise를 더하여(perturbation) 사람의 눈에는 차이가 없어 보이나 분류기는 잘못 분류 하도록 변형된 input
Adversarial example을 만들어 내는 행위를 adversarial attack이라 칭하며, 이를 방어하는 행위는 defense against adversarial attack 이라 부릅니다.
Adversarial attack의 종류와 의미는 다음과 같습니다(여기서 말하는 종류는 세세한 모델이 아니라 큰 흐름을 의미합니다):
- White-box attack - 공격자가 target model (e.g. classifier)의 parameters를 알고 있는 상황
- Black-box attack - 공격자가 target model (e.g. classifier)의 parameters를 모르는 상황
- Targeted attack - Adversarial example이 공격자가 원하는 class로 target classifier가 오분류 하도록 공격하는 방식
- Untargeted attack - Adversarial example이 true class가 아닌 어떠한 class로 target classifier가 오분류 하도록 공격하는 방식
한 가지 더 언급할 점은 black-box attack의 경우 공격자가 target model의 parameter를 모르기 때문에 공격이 불가능 합니다. 이에 공격자가 가지고 있는 데이터를 이용하여 target model의 분류 경계면을 근사하는 모델을 하나 만들어 낸 후 해당 모델의 parameter를 이용하여 adversarial example을 생성하는 flow를 가집니다. 이러한 특성상 black-box attack이 방어를 하는 입장에서는 white-box attack보다 쉬운 경향을 띄게 됩니다.

Fig 1.에서 위쪽 행은 clean images이며 아래쪽 행은 adversarial examples입니다. 이미지 아래 보이는 숫자와 기호는 모델이 위의 이미지를 보고 분류한 class를 나타내고 있습니다. 자율주행 자동차가 카메라로 사물을 인식하며 움직이다가 위와 같이 adversarial example을 만나 오분류를 하게 된다면 정말 끔찍한 일이 아닐 수 없습니다. 이러한 문제 인식을 통하여 모델 자체(연구) 뿐만 아니라 실생활에서도 본 문제를 꼭 해결해야 한다는 경각심을 가질 수 있습니다.
Explaining and Harnessing Adversarial Examples
Adversarial example이 대략 이런거구나 라고 생각 하셨을테니, 이제 본격적으로 본 논문을 소개 드리도록 하겠습니다.
본 논문에서는 adversarial example을 연구함으로써 엔지니어들의 학습 algoritms에 대한 blind spots을 찾을 수 있다고 언급하고 있습니다. 저에게는 이 말이 보다 사람다운 모델과 사람다운 학습 방식을 찾아야 한다는 의미로 들리더군요. 또한 이전까지는 adversarial example에 대하여 모델은 완전하나 이를 사용하는 engineer가 매우 비선형적인 Deep Neural Network (DNN)을 제대로 이해하지 못하고 모델을 제대로 학습시키지 못했기 때문에 발생하는 특수 케이스라고 여겼습니다. 하지만 본 논문에서는 이러한 추측이 틀렸음을 실험을 통하여 보여주고 있죠.
한 가지 재미 있는 사실은 본 논문에서 activation fuction으로 기존에 사용하던 sigmoid 혹은 ReLU를 사용하지 않고 RBF를 사용하면 adversarial noise에 보다 강건한 모델이 됨을 언급하고 있습니다.
다시 말해 DNN은 우리가 생각하는 것 만큼 non-linear 하지 않습니다.
생각을 해본다면 ReLU의 경우 최적화를 위해 태생이 매우 linear한 구조를 띄고 있습니다. 또한 sigmoid의 경우에도 모델을 학습 하다 보면 선형성을 지닌 부분에 많은 activation이 된다는 언급도 본 논문의 저자들은 잊지 않고 있네요.
하지만 이렇게 말로써 우리가 비선형적이라고 생각했던 모델은 사실 선형적이었어! 라고 한다면 이렇게까지 주목받는 논문이 되지 못했겠죠. 저자들은 매우 선형적인 공격 방식으로 생성한 adversarial example이 ‘비선형적’ 이라고 알려진 DNN (maxout)을 얼마나 잘 속이는지 실험을 통해 보여줍니다. 본 논문에서 사용하는 공격 방식은 Fast Gradient Sign Method (FGSM)이라고 불리며 식은 아래와 같습니다:
FGSM:
\(\eta = \epsilon(\nabla_x J(\theta, x, y))\),
where J는 target model의 목적식, $\theta$는 모델의 파라미터, x와 y는 각각 input과 output 이며 $\epsilon$은 노이즈의 크기를 결정하는 상수
위에서 구한 $\eta$를 원본 이미지에 더해주어 나온 이미지가 adversarial example이 되며 식은 아래와 같습니다:
\[\widetilde{x} = x + \eta\]
본 포스트의 상단부에서 말씀드린 adversarial example의 통상적인 정의에 따라 공격자는 사람이 인지하지 못할 만큼 작은 $\eta$를 원본 이미지에 더하여 target model을 속이는 것을 목표로 하고 있습니다.
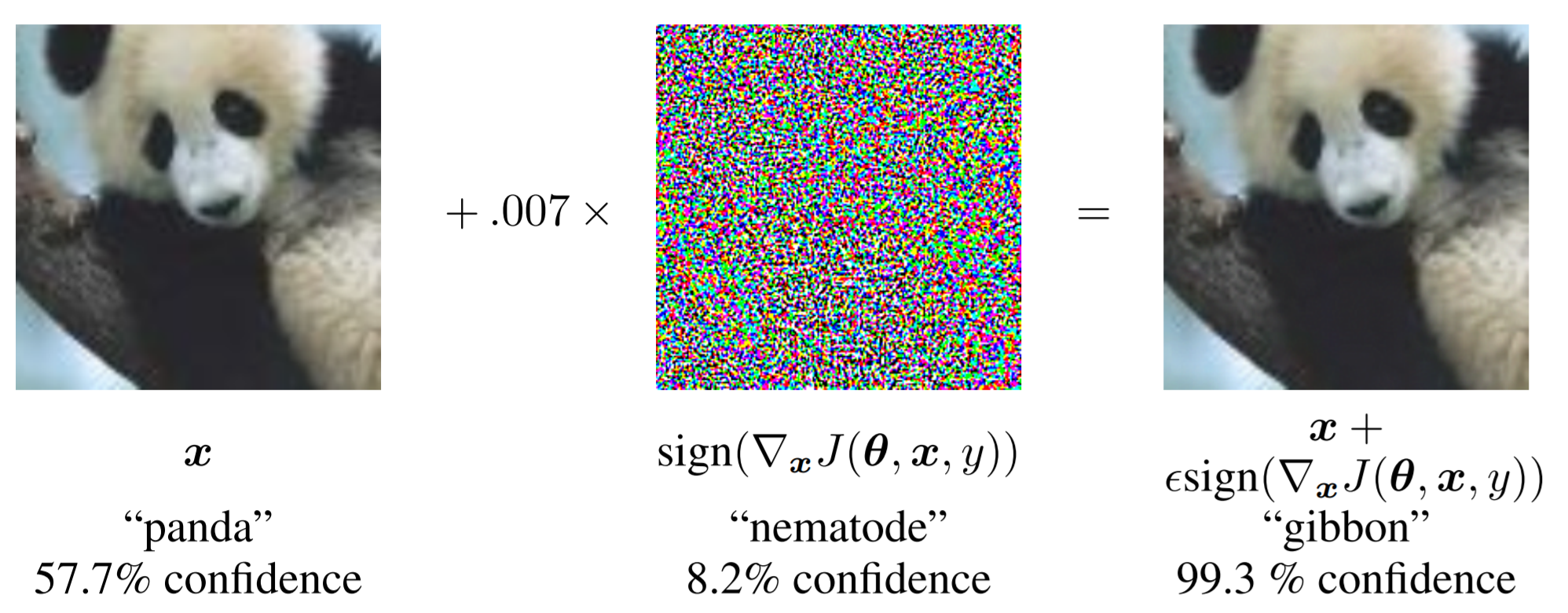
위의 2번 이미지를 보면 57.7%의 confidence를 가지고 팬더를 팬더로 인식하는 모델을 속이기 위하여 FGSM 방식으로 얻은 noise를 원본 이미지에 더해주고 있습니다. 이러한 과정을 거쳐 나온 이미지, adversarial example은 모델이 99.3%의 confidence로 긴팔 원숭이로 분류하고 있음을 확인 할 수 있습니다. 심지어 생성된 노이즈는 8.2%의 confidence로 선형동물로 인식되는 매우 의미 없는 문자 그대로의 nosie인데도 말이죠. 그리고 위에서 노이즈 앞에 보이시는 0.007이라는 수가 위 식에서 보셨던 noise의 크기를 결정하는 $\epsilon$입니다.
본 논문에서 저자들은 adversarial training이라는 개념을 통하여 이러한 공격을 어느정도 막을 수 있다고 언급하고 있습니다. 하지만 최근 연구 동향은 이러한 adversarial training이 여러 공격 패턴에 robust하지 못하다는 점을 조금 critical하게 생각하고 크게 사용하지 않는 추세 입니다. Adversarial training은 간략히 말해서 생성된 adversarial example을 모델이 학습하는 동안 clean data와 함께 학습시키는 방식 입니다. 직관적으로 생각해봐도 공격 방법이 늘어날수록 모든 공격방법으로 얻은 adversarial example을 획득한 다음 모든 data를 학습에 이용해야 하니 상당히 비효율 적일 것 같네요.
마무리
이로써 첫 번째 포스팅이 마무리 되었습니다. 어떠신가요? 저는 이 분야를 공부하면서 매우 새롭고 신비로웠습니다. 지금도 그렇구요. 여러분들도 조금의 흥미 그리고 믿고 있던 DNN에 대해서 회의를 느끼는 시간이 되셨으면 좋겠습니다.
Leave a comment