About GANs and Adversarial Training
AGENDA
1. GANs
2. Adversarial examples
3. Adversarial training
사실 본 포스트는 논문에 관한 이야기는 아닙니다. 하지만 지인이나 연구실 동료들과 함께 이야기를 하면서 adversarial training에 대하여 잘못 이해하고 있는 부분들이 있어 짧게 짚고 넘어가고자 합니다.
Ian Goodfellow
개인적으로 Ian Goodfellow를 참 좋아합니다. 그의 논문을 보고 있으면, 연구자로서 저런 생각을 할 수 있으면 얼마나 좋을까 라는 생각을 하지 않을 수 없습니다. 그의 연구 중 역시나 가장 대표 되는 업적은 GAN이 아닐까 싶습니다. 본 포스트의 목적과는 거리가 있지만, Ian 이야기를 한 김에 GAN에 대한 저의 생각을 짧게 말씀 드리려 합니다.
지금부터의 내용들은 순전히 저의 뇌피셜임을 말씀 드립니다

2014년 NIPS에 발표된 Generative Adversarial Nets은 deep learning에 한 획을 그은 연구였습니다. Nips 2016 Tutorial에서 Ian은 화폐 위조범과 경찰을 예로 들며 Generator와 Discriminator를 설명합니다. 위의 그림과 같이요. 실질적인 설명은 다들 너무나도 잘 아실테니 넘어가겠습니다.
우선, 드리고 싶은 질문이 있습니다:
GAN이 없다면 Deep learning은 어떤 역할을 하고 있을까?
현재 Deep learning의 task는 크게 분류와 생성으로 구분 지을 수 있을 것 같습니다. 여기서 생성이 빠진다면 DNN은 여전히 단순한 분류 작업만 하고 있을지도 모르겠습니다. 이처럼 GAN은 Yann LeCun이 극찬 했던 것 처럼 정말 대단하고도 참신한 아이디어 입니다.
그렇다면, GAN은 정말 ‘무’ 에서 창조된 ‘유’ 였을까요? 저의 생각은 ‘그렇지 않다’ 입니다.

위의 이미지는 통상적으로 우리가 그리는 GAN의 형태를 띄고 있습니다. 어디서 많이 보신 구조가 들어 있지 않으신가요? 네 맞습니다. 아래 보이시는 Auto encoder와 매우 흡사한 구조를 가지고 있죠.

아래 이미지에서 확인 할 수 있듯이 GANs의 Generator는 AE의 Decoder와, 그리고 Discriminator는 Encoder와 각각 맵핑됨을 알 수 있습니다.
여기서 중요한 점은 AE의 decoder는 GANs의 Generator와 같이 인풋을 받아 이미지를 생성하는 역할을 하지만 Generator와는 다르게 매우 예쁜 encoder가 잘 생성해준 latent vector를 받는다는 사실 입니다. 그에반해, Generator의 경우에는 모델의 최전선에 있기 때문에 누군가 만들어준 예쁜 인풋을 받을 수 없죠. 그래서 고민 끝에 나온 것이 z ~ N(0, I)인 vector를 무수히 많이 넣어 z를 latent vector로 만들자는 아이디어가 아니었을까 싶습니다. 실제로 이 z space를 latent space, z를 latent code라 부르고 있으며 이 space 를 잘 학습된 GAN을 통하여 역으로 추정하는 연구가 최근 Bolei Zhou 교수님을 필두로 매우 활발하게 진행되고 있습니다. 매우 재미있는 연구 분야니 GAN에 관심이 있으시면 꼭 찾아 보시기를 추천 드립니다.
제가 좋아하는 Ian Goodfellow 이야기가 나와서 신나서 지금까지 떠들었네요.
그럼 지금부터는 본 포스트의 목적인 Adversarial Training에 대하여 말씀 드리겠습니다.
Adversarial Example
Adversarial training을 제대로 이해하기 위해서는 adverasrial example에 대한 이해하 우선되어야 합니다. Adversarial example을 이야기 할 때 빠질 수 없는 논문 “Explaining and Harnessing Adversarial Examples”에서 본따 만든 아래 그림을 보시면 직관적인 이해가 편할 것 같습니다.

Figure 4에서 보여주고 있는 내용은, 우리가 보고 있는 real world data (여기서는 이미지)에 사람이 구분할 수 없는 noise (가운데 perturbation 부분)을 더해주면 최종적으로 사람은 noise를 더하기 전과 다름을 느낄 수 없으나 기계는 이를 다른 class로 예측 한다는 것 입니다. 위의 Figure를 살펴보면, 가장 왼쪽에 귀여운 고양이를 사람이나 분류기(여기서 가정은 이미 학습을 완료한 분류기 입니다.)나 모두 고양이로 인식할 것 입니다. 이 고양이 이미지에 가운데 있는 perturbation이라 불리는 noise를 더해주고 나면 가장 오른쪽 고양이가 나오는데 사람이 보기에는 여전히 너무나도 귀여운 고양이지만, 분류기가 보기에는 바나나로 보이게 됩니다. 이와같이, 사람에게는 전혀 인식되지 않으나 분류기에게는 치명적인 차이점을 제공하는 noise를 perturbation이라고 부르며 가장 오른쪽에 있는 이미지처럼 사람이 보기에는 정상적인 데이터와 다름이 없으나 기계가 보기에는 전혀 달라져버린 데이터를 adversarial example이라 부릅니다. 이러한 adversarial example을 비단 이미지뿐만 아니라 텍스트, 음성, 그래프와같이 우리가 생각하는 모든 input에서 생성될 수 있습니다.
그럼 위의 Perturbation은 어떤 식으로 생성이 되는 것일까요? 가장 대표적인 gradient-based 방식으로 살펴보겠습니다.
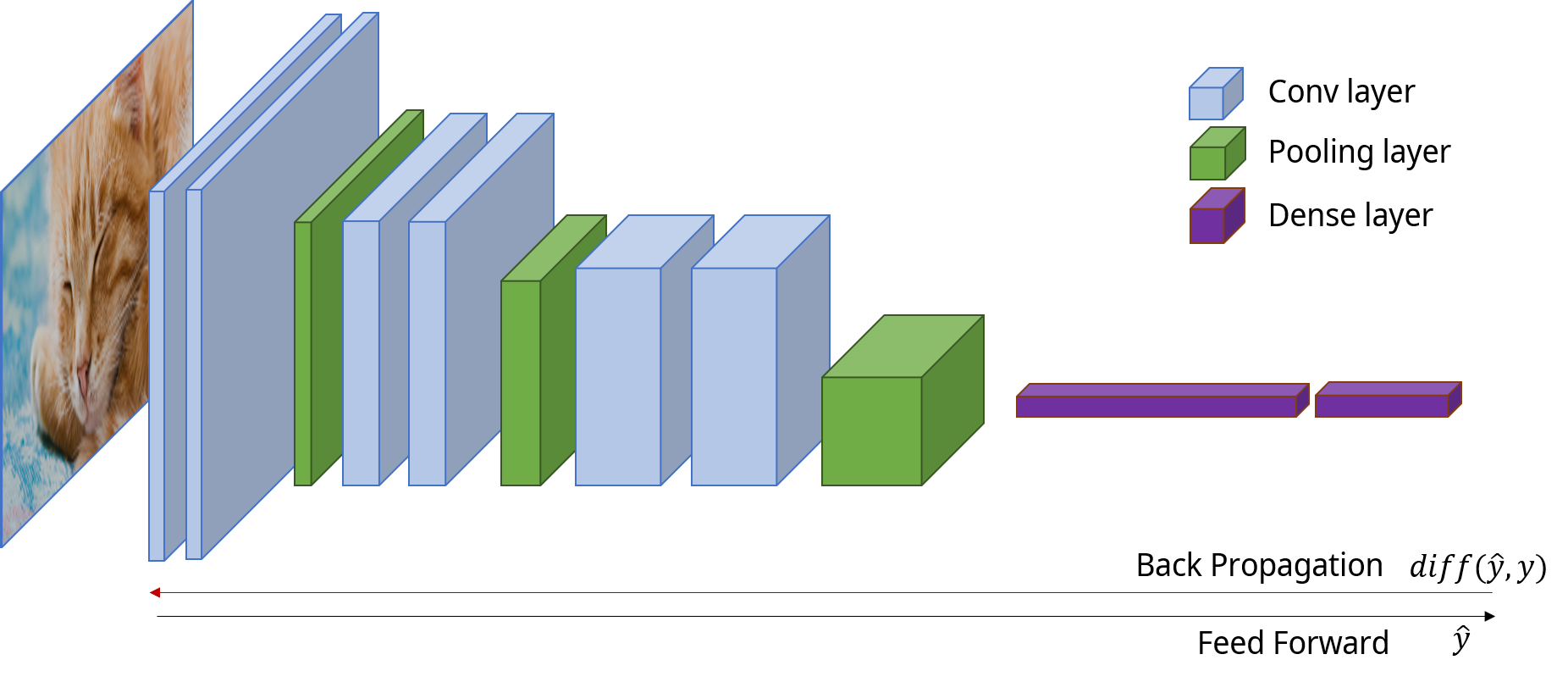
우선 우리가 익히 알고있는 것처럼, 모델의 weights는 input을 모델에 feeding한 후 모델의 예측값과 실제 레이블 사이의 오차를 바탕으로 backpropagation을 진행하며 update되게 됩니다. 이러한 반복적인 과정을 거치고 나면 loss가 수렴하며 학습이 완료되죠.
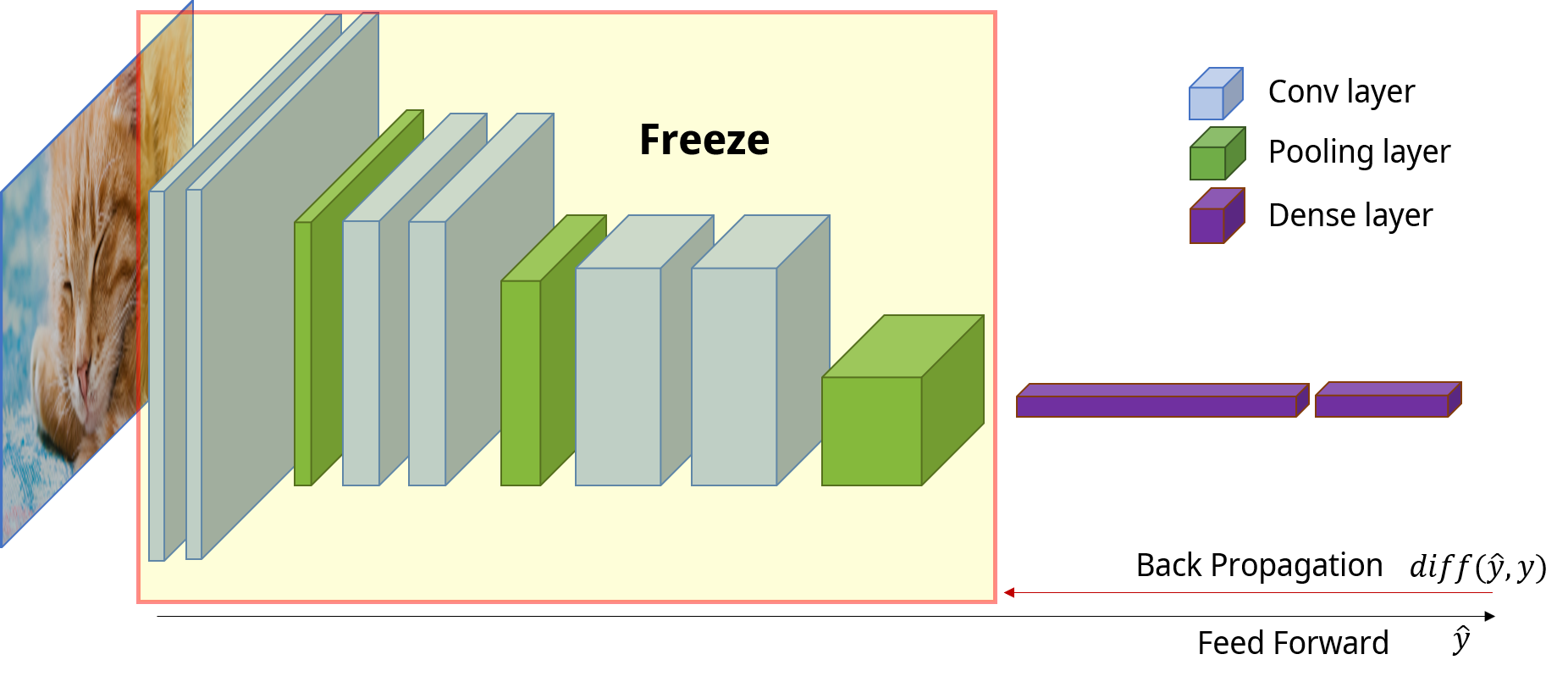
비슷한 컨셉으로 모델의 특정 부분, Figure 6에서는 dense layer (classifier) 이전 부분의 weights를 freeze한 후 backpropagation을 진행하여 freeze가 되지 않은 부분만 학습하는 기법을 finetuning이라 부릅니다. 그렇다면 전체 모델을 freeze하면 어떤 일이 발생할까요? 아래 Figure처럼 말이죠.

모델 전체를 freeze하면 대체 loss를 어디에 전파해야하지? 라는 생각이 드실것 같습니다. 그에대한 해답은 Fig 4에 있는데요, 이전 포스팅에서 설명드렸던 FGSM에서 perturbation을 구하는 목적식은 $sign(\nabla_xJ(\theta, x, y))$ 입니다. 여기서 $J$는 target classifier (분류기)의 목적식이 됩니다. 살펴보면 결국 $\theta$와 $x$를 통해 $\hat{y}$을 구한 후 $y$와의 비교를 통해 gradients를 구해갈텐데 위의 식을 잘 살펴보시면 그 대상이 $x$임을 알 수 있습니다. 다시 말해, 모델 전체의 weights를 fix시켜두고 loss에 대한 gradients를 input 단에서 구하는거죠. 마치 layer의 weights를 update시키는 것 처럼요!
약간 다른점은 일반적으로 weights를 업데이트 할 때에는 gradient에 learning rate를 곱해주는 방식으로 진행 되지만 FGSM에서는 gradient의 방향만 따온 후 거기에 $\epsilon$이라는 pyher-parameter를 곱해주어 perturbation을 구해준다는 것입니다.
지금까지 gradient-based 방식에서 perturbation을 어떻게 구하는지 살펴 보았습니다. 지금부터는 제가 본 포스트에서 최종적으로 하고싶었던 말씀을 드려보려 합니다.
Adversarial Training
우선 adversarial training에 대하여 간략하게 설명을 드리겠습니다.
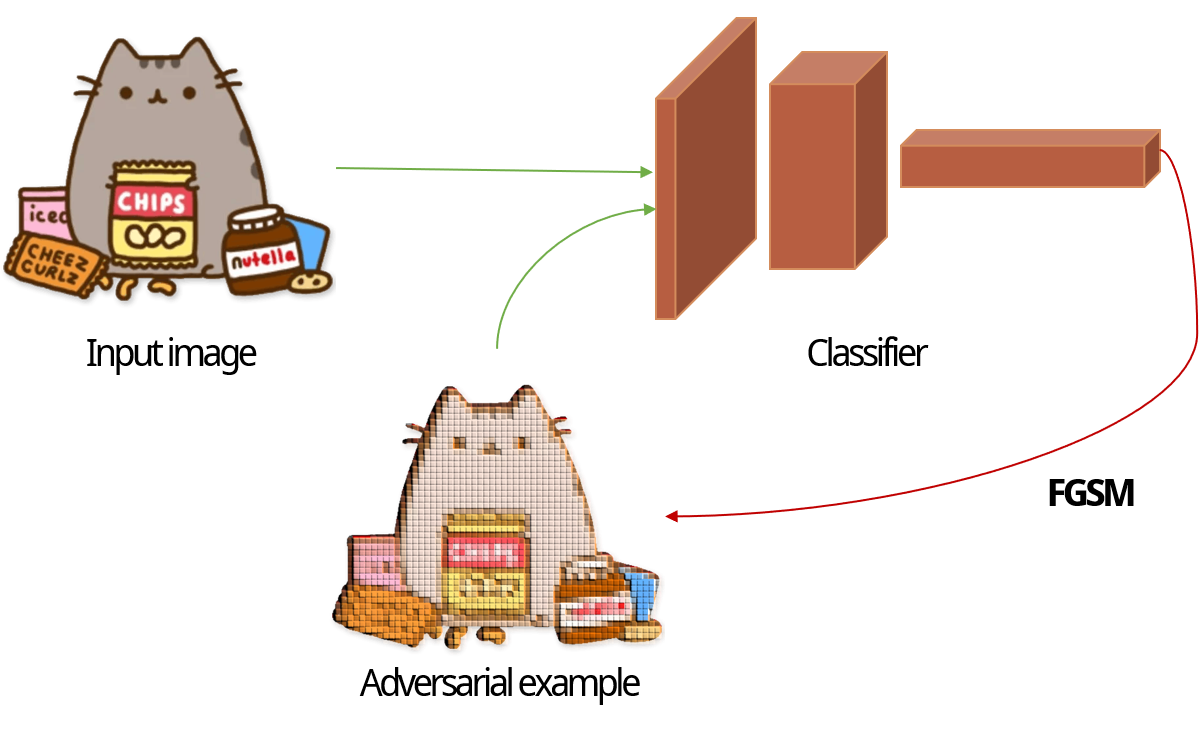
Figure 8에서 윗 부분만 살펴보면 일반적인 DNN을 학습시키는 과정과 동일함을 확인할 수 있습니다. Input을 feeding하고 모델이 결과를 산출하면 그 결과를 통해서 해당 모델을 업데이트 하는 방식 말이죠. Adversarial training은 이러한 일반적인 학습 중에 한 가지 트릭을 더해줍니다. 바로 학습을 진행하면서 내부적으로 adversarial example을 생성하고, 생성된 example을 다시 모델에 feeding함으로써 모델이 adversarial example에 robust할 수 있는 특릭 말이죠. FGSM을 예로 들자면, 모델을 구축하는 사람은 이미 FGSM의 목적식을 알고 있습니다. 우리 모두가 알고있죠! 그 목적식을 모델이 학습되는 중에 해당 모델에 적용시켜 매 시점 feeding되는 input에 맞는 adversarial example을 생성합니다. 순서를 살펴보자면 아래와 같겠죠:
- Normal input을 model에 feeding 한다
- 1 에서 산출된 예측값과 실제값을 통하여 모델을 업데이트 한다
- 1 에서 넣은 input에 대한 adversarial example을 2 에서 업데이트 된 모델을 통하여 생성한다.
- 3 에서 생성된 adversarial example을 2 의 모델에 다시 feeding한다
- 1 - 4 를 반복한다
Adversarial training의 기대 효과는 adversarial example에 robust한 모델 구축 입니다. 이러한 기대가 가능한 이유는 3번에서 들어가는 adversarial example에 대한 $hat{y}$는 매우 높은 확률로 잘못 되어 있지만, 이를 실제 $y$를 제공하고 모델을 업데이트 하는 과정에서 모델이 스스로 학습해 나가기 때문이죠. 실제로 여러 공격을 받고 한계를 보이고 있으나 adversarial training이 매우 직관적이고 특정한 상황 내에서는 매우 효과적인 방어 기법임은 틀림이 없습니다.
Misconception about Adversarial Training
그렇다면 제가 지금까지 저의 주변에서 가장 많이 봤던 adversarial training에 대한 오해는 무엇일까요? 바로 Robustness에서 오는 오해였습니다. 모델이 adversarial example에 robust하기를 기대하는 adversarial training을 마치 real data에 robust한 모델을 만드는 것으로 착각하는 것이죠. 우리가 real data에 robust한 모델을 만들기 위해서 흔히 “Data Augmentation”을 진행합니다. 다시 말해, 제가 가장 흔하게 본 오해는 adversarial training 내부에서 생성되는 adversarial example들을 마치 input에 대한 augmentation 기법으로 이해하는 것 이었습니다. 이런 이해가 왜 오해인지 간단한 실험을 통해 살펴보겠습니다. 실험은 CIFAR10에 대한 분류 task이며 사용한 model은 ResNet18 (custom)입니다. 모든 학습은 200 epochs 진행하였습니다.
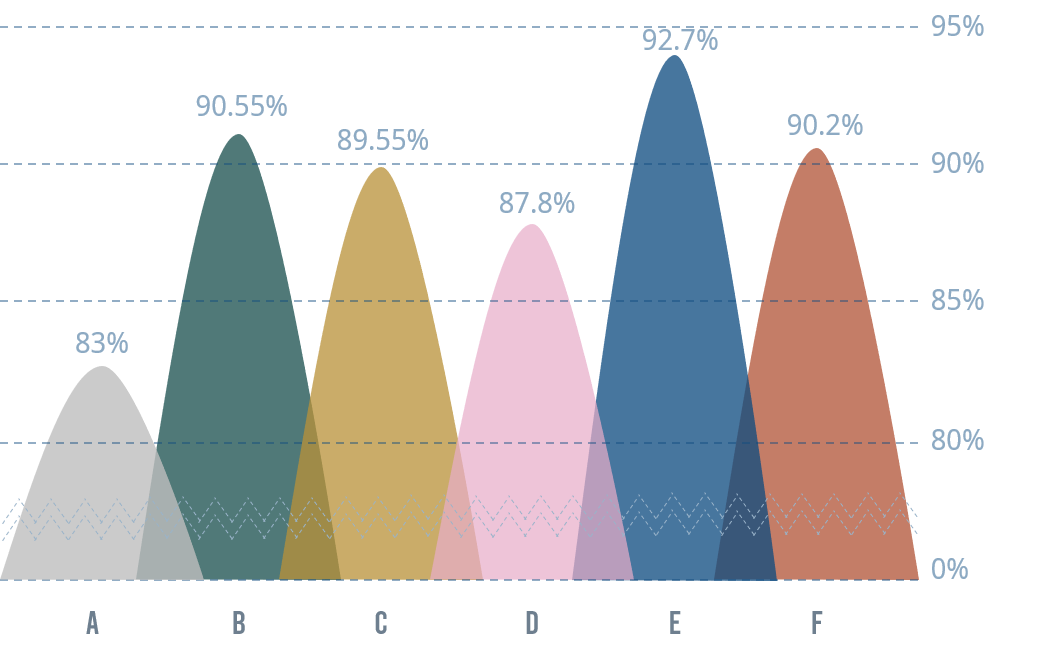
우선 데이터 augmentation의 효과에 대해 살펴보면 Figure 9와 같습니다. X축에 대한 설명은 아래와 같습니다:
- A: W/O augmentation
- B: Random crop
- C: Random horizontal flip
- D: Random rotation (15)
- E: ALL + SGD (optimizer)
- F: ALL + Adam (optimizer)
우선 A-E를 살펴 보면 data augmentation을 사용하지 않은 경우보다 사용한 경우 확실히 성능 향상이 있음을 볼 수 있습니다. E와 F가 조금 더 흥미로운 결과를 보여주는데 E는 나열된 모든 augmentation 기법을 사용한 후 optimizer로 SGD를 사용한 결과이며, F는 E와 같지만 optimizer로 Adam을 사용한 결과입니다. 이를 볼때 optimizer의 선택도 성능에 매우 중요한 역할을 한다는 것을 알 수 있습니다. 그렇다면 adversarial training도 이러한 결과를 보여줄까요?
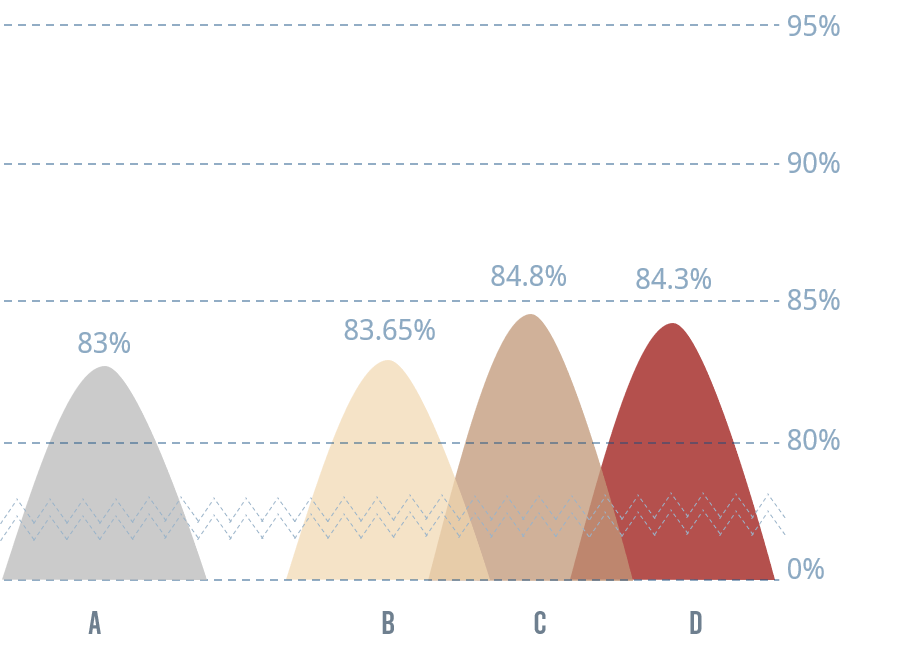
Figure 10을 보면 그렇지 않다는 것을 알 수 있습니다. 성능이 소폭 상승하기는 하였으나 Figure 9의 data augmentation 기법들과 같은 드라마틱한 차이는 없습니다. x축에 대한 설명은 아래와 같습니다:
- A: W/O augmentation
- B: 모델 학습 시작과 함께 adversarial training 진행
- C: 모델 학습이 어느정도 수렴한 후 adversarial training 진행
- D: 모델 학습을 완료한 후 dense layer에 대하여 fine-tuning을 adversarial training 으로 진행
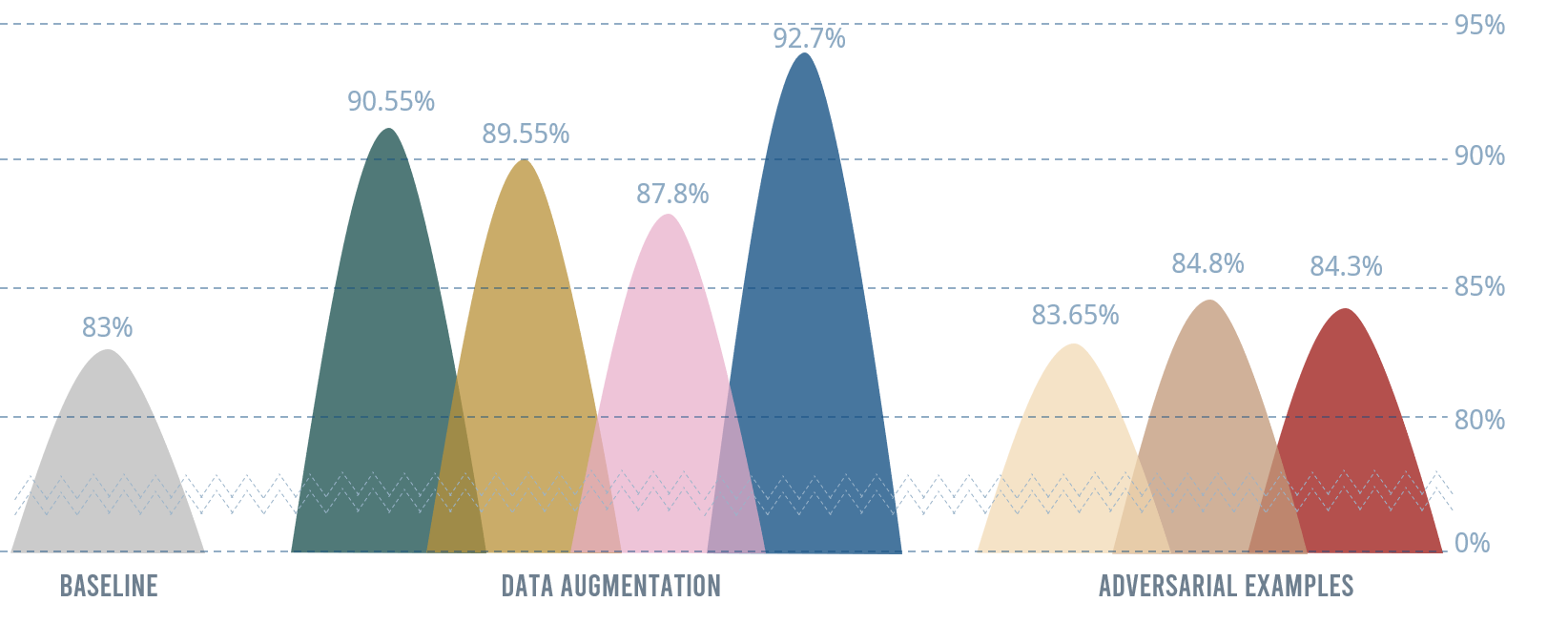
Figure 11에서는 모든 결과를 비교하고 있습니다. 이렇게 보면 그 차이가 얼마나 뚜렷한지를 알 수 있습니다. 결국 adversarial training은 data augmentation 효과가 없음을 알 수 있습니다.
마무리
주변에서 본 adversarial training에 대한 오해를 풀기위해 작성한 글입니다. Adversarial training으로 가기위하여 adverarial example에 대하여 간략하게 살펴보았으며, 제가 좋아하는 연구자가 등장하여 그의 대표 연구인 GAN에 대하여 저의 생각도 짧게 풀어보았습니다.
결론적으로 제가 주변에서 가장 많이 보았던 adversarial training에 대한 오해는 이 기법이 비단 adversarial example에 robust할 뿐만 아니라 real world data에도 robust할 것이다 였습니다. 다시 말해, data augmentation의 하나의 갈래라고 생각하는 분들이 정말 많았습니다. 본 포스트의 마지막 section에서 간단한 실험을 통하여 이러한 생각이 왜 오해가 되는지를 살펴보았습니다.
Leave a comment